
参考文章:
在 Kubernetes 生产调试中,日志记录起着至关重要的作用。它可以帮助您了解正在发生的事情、出了什么问题,甚至可能出了什么问题。作为 DevOps 工程师,您应该清楚地了解 Kubernetes 日志记录以解决集群和应用程序问题。
Kubernetes 日志采集原理
Kubernetes 日志记录如何工作
在 Kubernetes 中,大多数组件作为容器运行。在 Kubernetes 结构中,一个应用程序 pod 可以包含多个容器。大多数 Kubernetes 集群组件,如 api-server、kube-scheduler、Etcd、kube 代理等。作为容器运行。但是,kubelet 组件作为本机 systemd 服务运行。
通常,我们在 Kubernetes 上部署的任何 pod 都将日志写入 stdout 和 stderr 流,而不是将日志写入专用日志文件。但是,从每个容器流式传输到 stdout 和 stderr 以 JSON 格式存储在文件系统中。底层容器引擎完成这项工作,它旨在处理日志记录。例如 Docker 容器引擎。
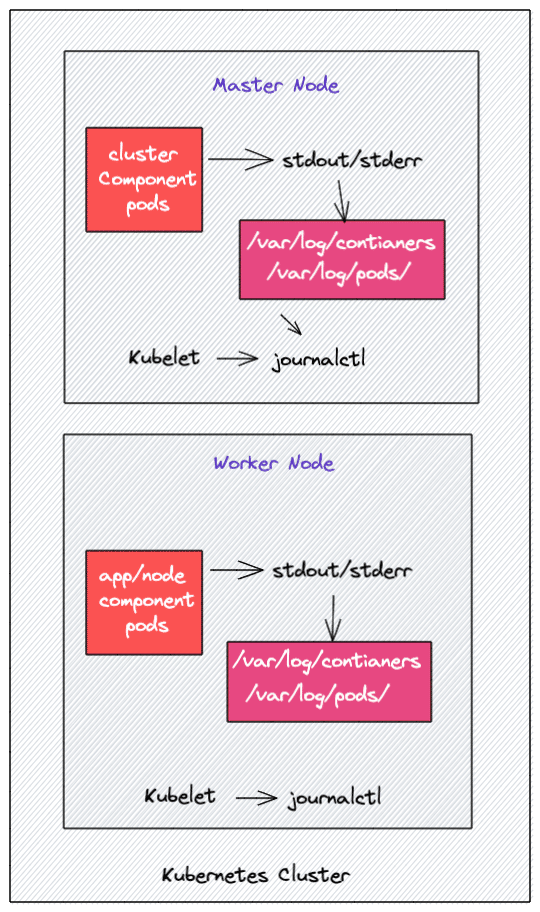
注意: 所有 Kubernetes 集群组件日志的处理方式与其他任何容器日志一样。
Kubelet 在所有节点上运行,以确保节点上的容器健康运行。它还负责运行静态 pod。如果 kubelet 作为 systemd 服务运行,它会将日志写入 journald。
此外,如果容器不将日志流式传输到 STDOUT 和 STDERR,您将无法使用“kubectl logs”命令获取日志,因为 kubelet 无法访问日志文件。
Kubernetes Pod 日志位置
您可以在每个工作节点的以下目录中找到 kubernetes pod 日志。
- /var/log/containers: 所有容器日志都存在于一个位置。
- /var/log/pods/: 在此位置下,容器日志被组织在单独的 pod 文件夹中,每个 pod 文件夹都包含单独的容器文件夹及其各自的日志文件。每个文件夹都有一个命名方案,如:
/var/log/pods/<namespace>_<pod_name>_<pod_id>/<container_name>/
此外,如果您的底层容器工程师是 docker,您将在 /var/lib/docker/containers 文件夹中找到日志。如果您登录到任何 Kubernetes 工作节点并转到 /var/log/containers 目录,您将找到该节点上运行的每个容器的日志文件。日志文件命名方案如下 /var/log/pods/<namespace>_<pod_name>_<pod_id>/<container_name>/。
此外,这些日志文件由 Kubelet 控制,因此当您运行
kubectl logs命令时,kubelet 会在终端中显示这些日志。
Kubelet 日志
对于 Kubelet,您可以使用 journalctl 从各个工作节点访问日志。例如,使用以下命令检查 Kubelet 日志。
1 | journalctl -u kubelet |
如果 Kubelet 在没有 systemd 的情况下运行,您可以在 /var/log 目录中找到 Kubelet 日志。
Kubernetes 容器日志格式
如前所述,所有日志数据都以 JSON 格式存储。因此,如果您打开任何日志文件,您会发现每个日志条目的三个键。
- Log: 实际日志数据
- stream: 写入日志的流
- time: 时间戳
如果您打开任何日志文件,您将看到上面提到的 JSON 格式的信息。例如,下面显示了 Nginx 日志文件的内容。使用 jq 美化输出。
1 | cat /var/log/containers/node-exporter-spq2w_kubesphere-monitoring-system_node-exporter-e2c2752af64615f3965d944c8eb5957d346ab301df4e21eaa9b8564d0eb6956b.log |jq |
Kubernetes 日志的类型
对于 Kubernetes,以下是不同类型的日志
- 应用程序日志:来自用户部署的应用程序的日志。应用程序日志有助于了解应用程序内部发生的情况。
- Kubernetes 集群组件:来自 api-server、kube-scheduler、etcd、kube-proxy 等的日志。这些日志可帮助您排查 Kubernetes 集群问题。
- Kubernetes 审计日志:API 服务器记录的与 API 活动相关的所有日志。主要用于调查可疑的 API 活动。
Kubernetes 日志架构
如果我们将 Kubernetes 集群作为一个整体,我们需要集中日志。没有默认的 Kubernetes 功能来集中日志。您需要设置一个集中式日志记录后端(例如:Elasticsearch)并将所有日志发送到日志记录后端。下图描述了一个高级 Kubernetes 日志架构。

让我们了解日志记录的三个关键组件:
- Logging Agent: 可以在所有 Kubernetes 节点中作为守护程序集运行的日志代理,将日志连续传送到集中式日志后端。日志代理也可以作为 sidecar 容器运行。例如,Fluentd。
- Logging Backend: 能够存储、搜索和分析日志数据的集中式系统。一个经典的例子是 Elasticsearch。
- Log Visualization: 以仪表板的形式可视化日志数据的工具。例如,Kibana。
Kubernetes 日志模式
这里介绍一些 Kubernetes 日志记录模式,以将日志流式传输到日志记录后端。 Kubernetes 集群日志记录的三种关键模式
- Node 级日志代理
- Streaming Sidecar 容器
- Sidecar 日志代理
节点级日志代理
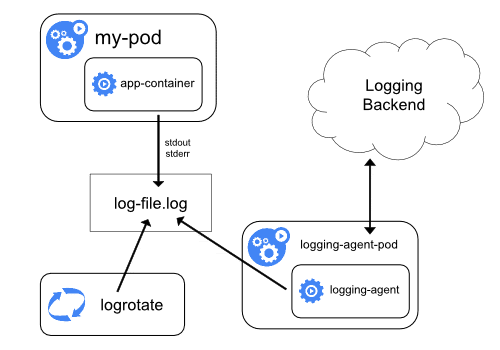
在这种方法中,节点级登录代理(例如:Fluentd)读取使用容器 STDOUT 和 STDERR 流创建的日志文件,然后将其发送到 Elasticsearch 等日志记录后端。这是一种常用的日志记录模式,并且工作得很好,没有任何开销。
Streaming sidecar 容器
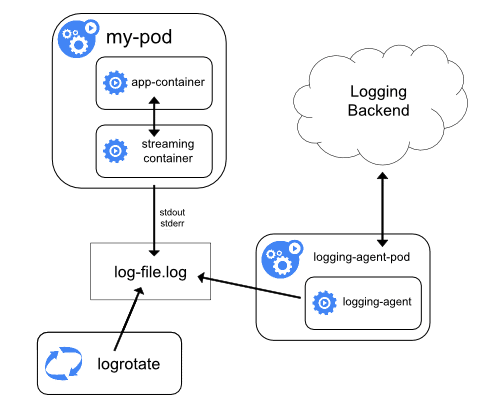
当应用程序无法将日志直接写入 STDOUT 和 STDERR 流时,这种流式 sidecar 方法很有用
因此,应用程序容器将所有日志写入容器内的文件。然后边车容器从该日志文件中读取数据并将其流式传输到 STDOUT 和 STDERR。
Sidecar 日志代理
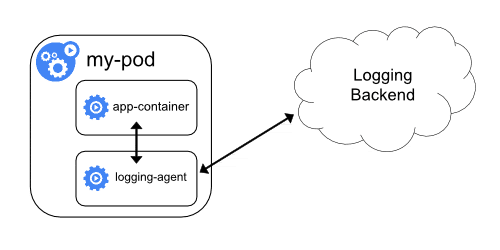
在这种方法中,日志不会流式传输到 STDOUT 和 STDERR。相反,带有日志代理的 sidecar 容器将与应用程序容器一起运行。然后,日志代理将直接将日志流式传输到日志后端。
这种方法有两个缺点:
- 将日志代理作为 sidecar 运行是资源密集型的。
- 您不会使用 kubectl logs 命令获取日志,因为 Kubelet 不会处理日志。
Kubernetes 日志工具
Kubernetes 最常用的开源日志堆栈是 EFK(Elasticsearch、Fluentd/Fluent-but 和 Kibana)。
- Elasticsearch – 日志聚合器
- Flunetd/Fluentbit – 日志代理(Fluentbit 是专为容器工作负载设计的轻量级代理)
- Kibana – 日志可视化和仪表板工具
在 Kubernetes 上部署 EFK Stack
在 Kubernetes 集群上运行多个应用程序和服务时,将所有应用程序和 Kubernetes 集群日志流式传输到一个集中式日志记录基础架构以方便日志分析更有意义。
EFK 架构
下图显示了我们将要构建的 EFK 堆栈的高级架构。
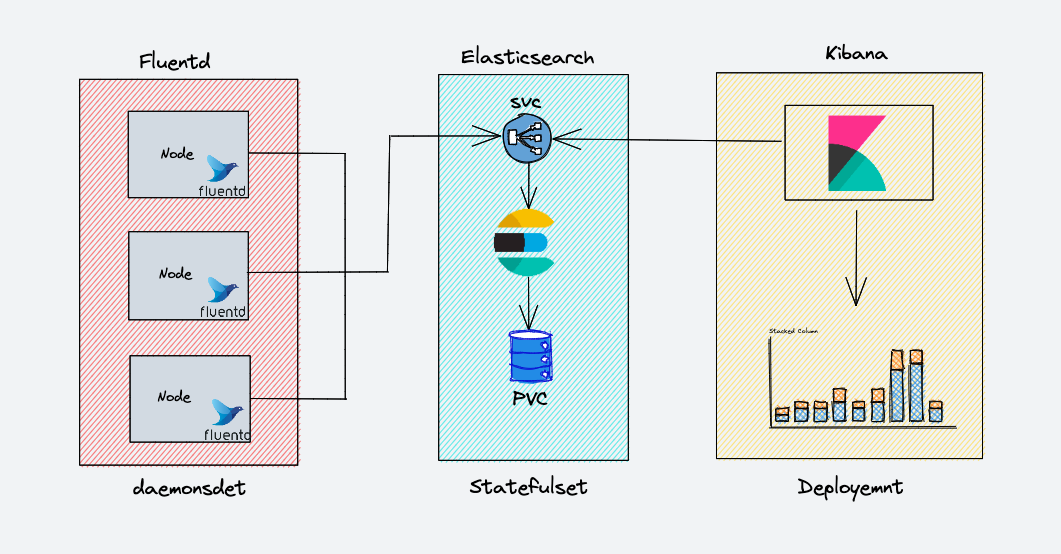
EKF 组件的部署方式如下:
Fluentd: 部署为 DaemonSet,因为它需要从所有节点收集容器日志。它连接到 Elasticsearch 服务端点以转发日志。
Elasticsearch: 部署为StatefulSet,因为它包含日志数据。我们还公开了 Fluentd 和 kibana 的服务端点以连接到它。
Kibana: 部署为 Deployment 并连接到 Elasticsearch 服务端点。
部署 Elasticsearch Statefulset
Elasticsearch 部署为 Statefulset,多个副本使用无头服务相互连接。无头 svc 有助于 pod 的 DNS 域。
将以下清单另存为 es-svc.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15kind: Service
apiVersion: v1
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node创建 es 的 svc
1
kubectl create -f es-svc.yaml
现在让我们创建 Elasticsearch 状态集。将以下清单另存为 es-sts.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.17.5
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "glusterfs"
resources:
requests:
storage: 10Gi虽然在生产环境中,我们需要使用 400-500Gbs 的容量来进行弹性搜索,但这里我们使用 10Gb PVC 进行部署以进行演示
创建 Elasticsearch StatefulSet
1
kubectl create -f es-sts.yaml
验证 Elasticsearch 部署,在 Elastisearch pod 进入运行状态后,让我们尝试验证 Elasticsearch StatefulSet。最简单的方法是检查集群的状态。为了检查状态,端口转发 Elasticsearch pod 的 9200 端口。
1
kubectl port-forward es-cluster-0 9200:9200
要检查 Elasticsearch 集群的运行状况,请再开一个终端,并运行以下命令。
1
curl http://localhost:9200/_cluster/health/?pretty
输出将显示 Elasticsearch 集群的状态。如果正确执行了所有步骤,则状态应显示为 “green”。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"cluster_name" : "k8s-logs",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 8,
"active_shards" : 16,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
部署 Kibana Deployment 和 Service
Kibana 可以创建为简单的 Kubernetes Deployment。如果您检查以下 Kibana 部署清单文件,我们会定义一个环境变量 ELASTICSEARCH_URL 来配置 Elasticsearch 集群端点。 Kibana 使用端点 URL 连接到 elasticsearch。
将 Kibana 部署清单创建为 kibana-deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: kibana:7.17.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch.default.svc.cluster.local:9200
ports:
- containerPort: 5601现在创建清单
1
kubectl create -f kibana-deployment.yaml
让我们创建一个 NodePort 类型的服务来通过节点 IP 地址访问 Kibana UI。我们使用 nodePort 进行演示。但是,理想情况下,具有 ClusterIP 服务的 kubernetes 入口用于实际项目实施。将以下清单另存为 kibana-svc.yaml
1
2
3
4
5
6
7
8
9
10
11
12apiVersion: v1
kind: Service
metadata:
name: kibana-np
spec:
selector:
app: kibana
type: NodePort
ports:
- port: 8080
targetPort: 5601
nodePort: 30001现在创建 kibana-svc。
1
kubectl create -f kibana-svc.yaml
现在您可以通过 http://
:30001 访问 Kibana 验证 Kibana 部署,在 Pod 进入运行状态后,让我们尝试验证 Kibana 部署。最简单的方法是通过集群的 UI 访问。要检查状态,请对 Kibana pod 的 5601 端口进行端口转发。如果你已经创建了 nodePort 服务,你也可以使用它。
1
kubectl port-forward <kibana-pod-name> 30002:5601
之后,通过 Web 浏览器访问 UI 或使用 curl 发出请求
1
curl http://localhost:30002/app/kibana
如果 Kibana UI 加载或出现有效的 curl 响应,那么我们可以断定 Kibana 运行正常。
部署 Fluentd DaemonSet
Fluentd 部署为守护程序集,因为它必须从集群中的所有节点流式传输日志。除此之外,它还需要特殊权限才能在所有命名空间中列出和提取 pod 的元数据。
Kubernetes 的 Service Accounts 用于为 Kubernetes 中的组件提供权限,以及集群角色和集群角色绑定。让我们继续创建所需的服务帐户和角色。
创建 Fluentd ClusterRole
Kubernetes 中的集群角色包含表示一组权限的规则。对于 fluentd,我们希望授予 pod 和命名空间的权限。
创建一个清单 fluentd-role.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch应用资源清单
1
kubectl create -f fluentd-role.yaml
创建 Fluentd Service Accounts
Kubernetes 中的服务帐户是为 pod 提供身份的实体。在这里,我们要创建一个用于 fluentd pod 的服务帐户。
创建清单 fluentd-sa.yaml
1
2
3
4
5
6apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
labels:
app: fluentd应用资源清单
1
kubectl create -f fluentd-sa.yaml
创建 Fluentd ClusterRoleBinding
Kubernetes 中的集群角色绑定将集群角色中定义的权限授予服务帐户。我们想在角色和上面创建的服务帐户之间创建一个角色绑定。
创建清单 fluentd-rb.yaml
1
2
3
4
5
6
7
8
9
10
11
12kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: default应用资源清单
1
kubectl create -f fluentd-rb.yaml
部署 Fluentd DaemonSet
将以下内容另存为 fluentd-ds.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.14.6-debian-elasticsearch7-arm64-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.default.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
- name: FLUENT_UID
value: "0"
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /data/docker/containers
readOnly: true
- name: varlogpods
mountPath: /var/log/pods
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /data/docker/containers
- name: varlogpods
hostPath:
path: /var/log/pods如果您检查部署,我们会使用两个环境变量,
FLUENT_ELASTICSEARCH_HOST和FLUENT_ELASTICSEARCH_PORT。 Fluentd 使用这些 Elasticsearch 值来发送收集的日志。应用资源清单
1
kubectl create -f fluentd-ds.yaml
配置 fluentd 使用自定义的配置文件
创建 fluentd-configmap.yaml 文件,内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
# 日志源配置
<source>
@id fluentd-containers.log # 日志源唯一标识符,后面可以使用该标识符进一步处理
@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址
pos_file /var/log/es-containers.log.pos # 检查点 Fluentd重启后会从该文件中的位置恢复日志采集
tag raw.kubernetes.* # 设置日志标签
read_from_head true
<parse> # 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern>
format json # JSON解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
<match raw.kubernetes.**> # 匹配tag为raw.kubernetes.**日志信息
@id raw.kubernetes
@type detect_exceptions # 使用detect-exceptions插件处理异常栈信息
remove_tag_prefix raw # 移除 raw 前缀
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
<filter kubernetes.**> # 添加 Kubernetes metadata 数据
@id filter_kubernetes_metadata
@type kubernetes_metadata
</filter>
<filter kubernetes.**> # 修复ES中的JSON字段
@id filter_parser
@type parser # multi-format-parser多格式解析器插件
key_name log # 在要解析的记录中指定字段名称。
reserve_data true # 在解析结果中保留原始键值对。
remove_key_name_field true # key_name 解析成功后删除字段。
<parse>
@type multi_format
<pattern>
format json
</pattern>
<pattern>
format none
</pattern>
</parse>
</filter>
<filter kubernetes.**> # 删除一些多余的属
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
<filter kubernetes.**> # 只采集具有logging=true标签的Pod日志
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
forward.input.conf: |- # 监听配置,一般用于日志聚合用
<source>
@id forward
@type forward
</source>
output.conf: |- # 路由配置,将处理后的日志数据发送到ES
<match **> # 标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成**
@id elasticsearch # 目标的一个唯一标识符
@type elasticsearch # 支持的输出插件标识符,输出到 Elasticsearch
@log_level info # 指定要捕获的日志级别,我们这里配置成 info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。
include_tag_key true
host elasticsearch # 定义 Elasticsearch 的地址
port 9200
logstash_format true # Fluentd 将会以 logstash 格式来转发结构化的日志数据
logstash_prefix k8s # 设置 index 前缀为 k8s
request_timeout 30s
<buffer> # Fluentd 允许在目标不可用时进行缓存
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>创建 configmap 资源
1
kubectl create -f fluentd-configmap.yaml
修改 fluentd-ds.yaml 文件,添加挂在 configmap 的配置项,如下所示
1
2
3
4
5
6
7
8
9
10... 省略 N 行 ...
volumeMounts:
- name: config-volume
mountPath: /fluentd/etc/conf.d
... 省略 N 行 ...
volumes:
- name: config-volume
configMap:
name: fluentd-config
... 省略 N 行 ...应用更改
1
kubectl apply -f fluentd-ds.yaml
等待 fluentd 服务重启完成,给正在运行的服务打标签,触发 Pod 更新
1
kubectl patch deployments.apps -n vbaas-c-ops-prod vbaas-c-ops-gateway -p '{"spec": {"template": {"metadata": {"labels": {"logging": "true"}}}}}'
Kubernetes EFK 最佳实践
Elasticsearch 广泛使用堆内存来过滤和缓存以获得更好的查询性能,因此应该有足够的内存用于弹性搜索。将超过一半的总内存分配给 elasticsearch 也可能会为操作系统功能留下太少的内存,这反过来又会妨碍 elasticsearch 的功能。所以要注意这一点! elasticsearch 占总堆空间的 40-50% 就足够了。
Elasticsearch 索引可以快速被填满,因此定期清理旧索引很重要。 Kubernetes cron 作业可以帮助您以自动化的方式定期执行此操作。
跨多个节点复制数据有助于灾难恢复并提高查询性能。默认情况下,elasticsearch 中的复制因子设置为 1。考虑根据您的用例使用此值。至少有 2 个是一个很好的做法。
已知被更频繁访问的数据可以放置在分配更多资源的不同节点中。这可以通过运行 cronjob 来实现,该 cronjob 定期将索引移动到不同的节点。
在 Elasticsearch 中,您可以将索引存档到低成本云存储(例如 aws-s3),并在您需要时将这些索引的数据进行恢复。如果您需要保存日志以进行审计和合规,这是最佳实践。
拥有多个具有专用功能的节点(如主节点、数据节点和客户端节点)有利于高可用性和容错。