
原文地址: Python 自动化运维快速入门 (第2版)
在日常的运维工作中一般都离不开与文本打交道,如日志分析,编码转换,ETL 加工等。本节从编码原理,文件操作,读写配置文件,解析 XML 等实用编程知识出发,希望能抛砖引玉,为读者在处理文本问题时提供可行的方法。
Python 编码解码
我们编写程序处理文本的时候,不可避免地遇到各种各样的编码问题,如果对编码解码过程一知半解,遇到这类问题就会很棘手。本节从编码解码的原理出发,结合 python 3 代码实例一步步揭开文本编码的面纱,编码解码的原理是相通的,学会编码解码,对学习其他编程语言也非常有帮助。
首先我们需要明白,计算机只处理二进制数据,如果要处理文本,就需要将文本转换为二进制数据,再由计算机进行处理。
将文本转换为二进制数据就是编码,将二进制数据转换为文本就是解码编码和解码要按照一定的规则进行,这个规则就是字符集。
以常见的 ASCII 编码为例,字符 ‘a’ 在 ASCII 码表中对应的数据是
97,二进制就是1100001。下面在 Python 中验证一下1
2
3
4
5
6
7
8
9
10
11In [1]: ord('a') # 查看 'a' 的 ASCII 码
Out[1]: 97
In [2]: bin(97) # 将 97 转换为二进制
Out[2]: '0b1100001'
In [3]: chr(97) # 将十进制数字转换为 ASCII 字符
Out[3]: 'a'
In [4]: bin(ord('a'))
Out[4]: '0b1100001'
由于 ASCII 编码只占用一个字节,也就是二进制8位,共有 2^8^ 256 种可能,完全可以覆盖英文大小写字母及特殊符号。而我们中文汉字远超过 256 个,使用 ASCII 编码的一个字节来处理中文显然是不够用的,于是我国就制定了支持中文的 GB2312 编码,使用两个字节,可以支持 2^16^ 共 65536 种汉字,可以覆盖常用的中文汉字 60370 个(当代《汉语大字典》(2010年版) 收字 60370 个)。
例如: 汉字的 “汉”
1
2
3
4
5
6
7
8In [5]: "汉".encode('gb2312')
Out[5]: b'\xba\xba'
In [6]: (b'\xba\xba').decode('gb2312')
Out[6]: '汉'
In [7]: list("汉".encode('gb2312'))
Out[7]: [186, 186]
在这里介绍几种常见的中文编码:
- GB2312 或 GB2312-80 是中国国家标准简体中文字符集,共收录 6763 个汉字,同时收录了包括拉丁字母,希腊字母,日文平假名及片假名字母,俄语西里尔字母在内的 682 个字符;
- GBK 即汉字内码扩展规范,共收录 21886 个汉字和图形符号;
- GB18030 与 GB2312-1980 和 GBK 兼容,共收录汉字 70244 个,是一二四字节变长编码。
由上可以看出支持的汉字范围: GB18030 > GBK > GB2312
对于一些生僻字,可能需要 GBK 或 GB18030 进行编码,如 “祎”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19In [8]: "祎".encode("gb2312") # GB2312 编码表中没有 祎 字的编码,所以会报错
---------------------------------------------------------------------------
UnicodeEncodeError Traceback (most recent call last)
<ipython-input-8-39b5598b3ca4> in <module>
----> 1 "祎".encode("gb2312")
UnicodeEncodeError: 'gb2312' codec can't encode character '\u794e' in position 0: illegal multibyte sequence
In [9]: "祎".encode("gbk")
Out[9]: b'\xb5t'
In [10]: list("祎".encode("gbk"))
Out[10]: [181, 116]
In [11]: "祎".encode("gb18030")
Out[11]: b'\xb5t'
In [12]: list("祎".encode("gb18030"))
Out[12]: [181, 116]
这仅仅是适用于中文文本的一个编码,全世界有上百种语言,每种语言都设计自己都特的编码,这样计算机在跨语言进行信息传输时还是无法沟通(出现乱码)的,于是 Unicode 编码应运而生,Unicode 使用 2~4 个字节编码,已经收录 136690 个字符,并且还在一直不断扩张中。把所有语言统一到一套编码中,这套编码就是 Unicode 编码。 使用 Unicode 编码,无论处理什么文本都不会出现乱码问题。Unicode 编码使用两个字节(16位bit) 表示一个字符,比较偏僻的字符需要使用4个字节。
Unicode 起到以下几个作用:
- 直接支持全球所有语言,每个国家都可以不再使用自己之前的旧编码了,用 Unicode 就可以;
- Unicode 包含了与全球所有国家编码的映射关系。
几乎所有的系统,编程语言都默认支持 Unicode。但是新的问题又来了,如果一段纯英文文本,用 Unicode 编码存储就会比用 ASCII 编码多占用一倍空间!存储和网络传输时一般数据都会非常多。为了解决上述问题,UTF 编码应运而生,UTF 编码将一个 Unicode 字符编码成 16 个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符会被编码成 46 个字节。注意,从 Unicode 到 UTF 并不是直接对应的,而是通过一些算法和规则来转换的。
UTF 编码有以下三种:
- UTF-8: 使用 1,2,3,4 个字节表示所有字符,优先使用 1 个字节,若无法满足,则增加一个字节,最多 4 个字节。英文占 1个字节,欧洲语系占 2 个字节,东亚占 3 个字节,其他及特殊字符占 4 个字节;
- UTF-16: 使用 2,4 个字节表示所有字符,优先使用 2 个字节,否则使用 4 个字节表示;
- UTF-32: 使用 4 个字节表示所有字符。
例如汉字的 “汉”,在 UTF-8 字符集中占用 3 个字节
1
2In [1]: list("汉".encode("UTF-8"))
Out[1]: [230, 177, 137]而英文无论采用哪种编码,都是一致的。如果使用纯英文编写代码,就基本不会遇到编码问题。如 ‘a’ 在 ASCII,GBK,UTF-8 中的编码结果都是一致的
1
2
3
4
5
6
7
8In [2]: list('a'.encode('ASCII'))
Out[2]: [97]
In [3]: list('a'.encode('GBK'))
Out[3]: [97]
In [4]: list('a'.encode('UTF-8'))
Out[4]: [97]下面结合 Python 代码实例来理解编码,代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 本文件应该保存为 utf-8 编码,否则会报错
str = "我是中国人"
print(f'Unicode 字符串为 "{str}"')
byte0 = str.encode("utf-8")
print(f'Unicode 字符串 "{str}" 以 utf-8 编码得到的字节串是 [{byte0}]')
str0 = byte0.decode("utf-8")
print(f'将 utf-8 字节串 [{byte0}] 解码得到的 Unicode 字符串 "{str0}"')
byte1 = str.encode("gbk")
print(f'Unicode 字符串 "{str}" 以 gbk 编码得到的字节串是 [{byte1}]')
str1 = byte1.decode("gbk")
print(f'将 gbk 字节串 [{byte1}] 解码得到的 Unicode 字符串 "{str1}"')
print(f'以文本方式将 Unicode 字符串 "{str}" 写入 a.txt')
with open('a.txt', 'w', encoding='gbk') as f:
f.write(str)
print(f'以文本方式读取 a.txt 的内容')
with open('a.txt', 'r', encoding='gbk') as f:
print(f.read())我们使用 VIM 编辑器编写
str_encode_decode.py文件,在第一行指定 Python 解释器以及使用 UTF-8 编码解码源文件,并保存为 UTF-8 编码的文本文件,然后运行程序。这一编码解码的过程如下图所示
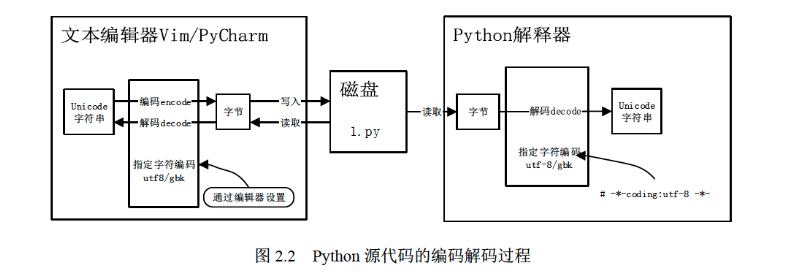
上图中的 Unicode 字符串就是我们在编辑器中看到的字符串,如 “我是中国人” 这个字符串,在 Python 3 中所定义的字符串就是 Unicode 字符串。Unicode 字符串可以编码为任意编码格式的字节码,解码时使用同一编码进行解码即可得到原来的 Unicode 字符串。
上述代码的运行结果如下:
1
2
3
4
5
6
7
8Unicode 字符串为 "我是中国人"
Unicode 字符串 "我是中国人" 以 utf-8 编码得到的字节串是 [b'\xe6\x88\x91\xe6\x98\xaf\xe4\xb8\xad\xe5\x9b\xbd\xe4\xba\xba']
将 utf-8 字节串 [b'\xe6\x88\x91\xe6\x98\xaf\xe4\xb8\xad\xe5\x9b\xbd\xe4\xba\xba'] 解码得到的 Unicode 字符串 "我是中国人"
Unicode 字符串 "我是中国人" 以 gbk 编码得到的字节串是 [b'\xce\xd2\xca\xc7\xd6\xd0\xb9\xfa\xc8\xcb']
将 gbk 字节串 [b'\xce\xd2\xca\xc7\xd6\xd0\xb9\xfa\xc8\xcb'] 解码得到的 Unicode 字符串 "我是中国人"
以文本方式将 Unicode 字符串 "我是中国人" 写入 a.txt
以文本方式读取 a.txt 的内容
我是中国人如果编写 Python 程序时未指定 Python 解释器以何种编码来解码的话,Python 解释器会使用系统的默认编码。默认编码可以通过
sys.getdefaultencoding()来查看 Python 解释器会使用的默认编码,1
2
3
4In [1]: import sys
In [2]: sys.getdefaultencoding()
Out[2]: 'utf-8'
Python 文件操作
用 Python 或其他语言编写应用程序时,若想把数据永久保存下来,必须保存于硬盘中,这就涉及我们编写应用程序来操作硬件,而应用程序是无法直接操作硬件的,需要通知操作系统,由操作系统完成复杂的硬件操作。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘的虚拟接口,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
操作文件的流程如下:
- 打开文件,得到一个文件句柄,并复制给一个变量;
- 通过句柄对文件进行操作;
- 关闭文件。
普通文件操作
Python 文件操作也是非常简单,只需要一个 open 函数返回一个文件句柄,无需导入任何模块
1 | In [5]: f = open('a.txt', encoding='gbk') |
open 函数的原型如下:
1 | open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) |
file: 一个表示文件名称的字符串,如果文件不在程序当前路径,就需要在前面加上相对路径或绝对路径
mode: 可选参数,指示要打开文件的方式,若不指定,则默认以读文本的方式打开文件。
以下是可选的打开文件方式:
字符串 含义 ‘r’ 以读的方式打开文件(默认) ‘w’ 以写的方式打开文件,会先清空文件 ‘x’ 创建一个新文件,然后以写的方式打开 ‘a’ 以写的方式打开文件,如果文件已存在,就在文件的最后位置追加内容 ‘b’ 以二进制方式打开文件,可以和读写命令共用 ‘t’ 以文本方式(默认) ‘+’ 以读写方式打开文件,用于更新文件 ‘U’ 通用的换行模式(弃用) 默认的打开方式是 ‘rt’(mode=’rt’)。Python 是区分二进制方式和文本方式,当以二进制方式打开一个文件时(mode 参数后面跟 ‘b’),返回一个未经解码的字节对象;当以文本方式打开文件时(默认是以文本方式打开,也可以 mode 参数后面跟 ‘t’),返回一个按系统默认编码或参数 encoding 传入的编码来解码的字符串对象。
buffering: 是一个可选的参数,buffering=0 表示关闭缓冲区(仅在二进制方式打开时可用);buffering=1 表示选择行缓冲区(仅在文本方式打开时可用);buffering 大于 1 时,其值代表固定大小的块缓冲区的大小。当不指定该参数时,默认的缓冲策略是这样的: 二进制文件使用固定大小的块缓冲区,文本文件使用行缓冲区。
- 先开看一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Author: ZhouBin
# @Email: 2350686113@qq.com
# @Date: 2021/10/20
# @Last modified by: ZhouBin
# @Last modified time: 2021/10/20
# @Descriptions:
f = open("wb.txt", "w", encoding="utf-8")
f.write("测试以 w 方式写入,如果文件已存在,则清空内容后写入;如果文件不存在,则创建\n")
f.close()
f = open("wb.txt", "a", encoding="utf-8")
f.write("测试以 a 方式写入,如果文件已存在,则在文件内容最后追加写入;如果文件不存在,则创建")
f.close()
f = open("wb.txt", "r", encoding="utf-8")
# 以文本方式读, f.read() 返回字符串对象
data = f.read()
print(type(data))
print(data)
f.close()
f = open("wb.txt", "rb")
# 以二进制方式读,f.read() 返回字节对象
data = f.read()
print(type(data))
print(data)
print('将读取的字符对象解码: ')
print(data.decode('utf-8'))
f.close()将上述代码保存为
read_write_file.py,运行结果如下1
2
3
4
5
6
7
8<class 'str'>
测试以 w 方式写入,如果文件已存在,则清空内容后写入;如果文件不存在,则创建
测试以 a 方式写入,如果文件已存在,则在文件内容最后追加写入;如果文件不存在,则创建
<class 'bytes'>
b'\xe6\xb5\x8b\xe8\xaf\x95\xe4\xbb\xa5 w \xe6\x96\xb9\xe5\xbc\x8f\xe5\x86\x99\xe5\x85\xa5\xef\xbc\x8c\xe5\xa6\x82\xe6\x9e\x9c\xe6\x96\x87\xe4\xbb\xb6\xe5\xb7\xb2\xe5\xad\x98\xe5\x9c\xa8\xef\xbc\x8c\xe5\x88\x99\xe6\xb8\x85\xe7\xa9\xba\xe5\x86\x85\xe5\xae\xb9\xe5\x90\x8e\xe5\x86\x99\xe5\x85\xa5\xef\xbc\x9b\xe5\xa6\x82\xe6\x9e\x9c\xe6\x96\x87\xe4\xbb\xb6\xe4\xb8\x8d\xe5\xad\x98\xe5\x9c\xa8\xef\xbc\x8c\xe5\x88\x99\xe5\x88\x9b\xe5\xbb\xba\n\xe6\xb5\x8b\xe8\xaf\x95\xe4\xbb\xa5 a \xe6\x96\xb9\xe5\xbc\x8f\xe5\x86\x99\xe5\x85\xa5\xef\xbc\x8c\xe5\xa6\x82\xe6\x9e\x9c\xe6\x96\x87\xe4\xbb\xb6\xe5\xb7\xb2\xe5\xad\x98\xe5\x9c\xa8\xef\xbc\x8c\xe5\x88\x99\xe5\x9c\xa8\xe6\x96\x87\xe4\xbb\xb6\xe5\x86\x85\xe5\xae\xb9\xe6\x9c\x80\xe5\x90\x8e\xe8\xbf\xbd\xe5\x8a\xa0\xe5\x86\x99\xe5\x85\xa5\xef\xbc\x9b\xe5\xa6\x82\xe6\x9e\x9c\xe6\x96\x87\xe4\xbb\xb6\xe4\xb8\x8d\xe5\xad\x98\xe5\x9c\xa8\xef\xbc\x8c\xe5\x88\x99\xe5\x88\x9b\xe5\xbb\xba'
将读取的字符对象解码:
测试以 w 方式写入,如果文件已存在,则清空内容后写入;如果文件不存在,则创建
测试以 a 方式写入,如果文件已存在,则在文件内容最后追加写入;如果文件不存在,则创建从上面的例子可以看出,以二进制读取文件时,读取的是文件字符串的编码(以 encoding 指定的编码格式进行编码的内容),将读取的字节码对象解码,可以得出原字符串。
常见的文件操作方法如下表
名称 功能 f.read() 读取文件所有内容,光标移动到文件末尾 f.readline() 读取一行内容,光标移动到第二行的首部 f.readlines() 读取每一行,存放于列表中 f.write(‘111\n222\n’) 针对文本模式的写,需要自己写换行符 f.write(‘111\n222\n’.encode(‘utf-8’)) 针对二进制模式的写,需要自己写换行符 f.writelines([‘333\n’, ‘444\n’]) 文本模式的写 f.writelines([bytes(‘333\n’, encoding=’utf-8’),’444\n’.encode(‘utf-8’)]) 二进制模式的写 f.readable() 文件是否可读 f.writable() 文件是否可写 f.closed 文件是否关闭 f.encoding 如果文件打开模式为 b,则没有该属性 f.flush() 立刻将文件的内容从内存写入到磁盘
读取文件内位置的定位方法
通过 read 方法传入参数,如 read(3),当文件打开方式为文本模式时,代表读取3个字符,当文件打开方式为二进制模式时,代表读取3个字节。
以字节为单位定位,如 seek,tell 等方法。其中 seek 有3种移动方式: 0、1、2;其中 1 和 2 必须在二进制模式下进行,但无论哪种方式,都是以 bytes 为单位移动的。f.tell() 返回文件对象当前所处的位置,它是从文件开头开始算起的字节数。如果要改变文件当前的位置,可以使用 f.seek(offset, from_what) 函数。from_what 如果是0,则表示开头;如果是1,则表示当前位置;如果是2 则表示文件的结尾。例如:
- seek(x, 0) 表示从文件起始位置,即文件首行收个字符开始移动 x 个字符;
- seek(x, 1) 表示从当前位置向后移动 x 个字符;
- seek(-x, 2) 表示从文件的结尾向前移动 x 个字符。
示例
示例1: 在文件中定位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19In [1]: f = open('tmp.txt', 'rb+') # 文件必须存在,否则会报错
In [2]: f.write(b"abcdefghi")
Out[2]: 9
In [3]: f.seek(5) # 移动到文件的第六个字节
Out[3]: 5
In [4]: f.tell() # 当前的位置
Out[4]: 5
In [5]: print(f.read(1)) # 打印一个字符
b'f'
In [6]: f.seek(-3, 2) # 移动到文件的倒数第三个字节
Out[6]: 6
In [7]: print(f.read(1))
b'g'示例2: 基于 seek 实现类似 Linux 命令行的 tail -f 功能(文件名为 lx_tailf.py)
1
2
3
4
5
6
7
8
9
10
11import time
with open('tmp.txt', 'rb') as f:
f.seek(0, 2) # 将光标移动至文件末尾
while True: # 实时显示文件新增的内容
line = f.read()
if line:
print(line.decode('utf-8'), end='')
else:
time.sleep(0.2) # 读取完毕后短暂的睡眠当 tmp.txt 追加新的内容时,新内容会被程序立即打印出来。
大文件的读取
当文件较小时,我们可以一次性全部读入内存,对文件的内容做任意修改,再保存至磁盘,这一过程会非常快。
如下代码将 a.txt 中的字符串 str1 替换为 str2
1
2
3
4
5
6
7
8
9
10
11import os
with open('a.txt') as read_f, open('.a.txt.swap', 'w') as write_f:
data = read_f.read() # 全部读入内存,如果文件很大,则会很卡
data = data.replace('str1', 'str2') # 在内存中完成修改
write_f.write(data) # 一次性写入新文件
os.remove('a.txt')
os.rename('.a.txt.swap', 'a.txt')当文件很大的时候,如 GB 级的文本文件,上面的代码运行将会非常缓慢,此时我们需要使用文件的可迭代方式将文件的内容逐行读入内存,再逐行写入新文件,最后用新文件覆盖源文件。
对大文件进行读写
1
2
3
4
5
6
7
8
9
10import os
with open('a.txt') as read_f, open('.a.txt.swap', 'w') as write_f:
for line in read_f: # 对可迭代对象 read_f 进行逐行操作,防止内存溢出
line = line.replace('str1', 'str2')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap', 'a.txt')本示例中的大文件 a.txt,当我们打开文件时,会得到一个可迭代对象 read_f,对可迭代对象进行逐行读取,可防止内存溢出,也会加快处理速度。
处理大数据还有多种方法,如:
- 通过 read(size) 增加参数,指定读取的字节数
1
2
3
4while True:
block = f.read(1024)
if not block:
break- 通过 readline,每次只读取一行
1
2
3
4while True:
line = f.readline()
if not line:
breakfile 对象常见的函数如下表所示:
函数 功能 file.close() 关闭文件,关闭文件后不能再进行读写操作 file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件,而不是被动等待输出缓冲区写入 file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型),可以用在如 os 模块的 read 方法等一些底层操作上 file.isatty() 如果文件连接到一个终端设备,则返回 True,否则返回 False file.next() 返回文件的下一行 file.read([size]) 从文件读取指定的字节数,如果未给定或为负,则读取所有 file.readline([size]) 读取整行,包括 “\n” 字符 file.readlines([sizeint]) 读取所有行并返回列表,若给定的 sizeint > 0, 则返回总和为 sizeint 字节的行,实际读取的值可能比 sizeint 大,因为需要填充缓冲区 file.seek(offset[, whence]) 设置文件当前位置 file.tell() 返回文件当前位置 file.truncate([size]) 根据 size 参数截取文件,size 参数可选 file.write(str) 将字符串写入文件,没有返回值 file.writelines(sequence) 向文件写入一个序列字符串列表,如果需要换行,则加入每行的换行符
序列化和反序列化
什么是序列化和反序列化呢?我们可以这样简单的理解:
- 序列化: 将数据结构或对象转换成二进制串的过程;
- 反序列化: 将在序列化过程中所生成的二进制串转换成数据结构或对象的过程。
Python 的 pickle 模块实现了基本的数据序列化和反序列化。通过 pickle 模块的序列化操作,我们能够将程序中运行的对象信息保存到文件中并永久存储。通过 pickle 模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本方法如下:
1
2
3
4
5# 序列化,将对象 obj 保存至文件中
pickle.dump(obj, file, protocol=None, *, fix_imports=True, buffer_callback=None)
# 反序列化,从文件中恢复对象,并将其重构为原来的 Python 对象
x = pickle.load(file, *, fix_imports=True, encoding='ASCII', errors='strict', buffers=())
序列化示例(example_serialize.py)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import pickle
# 字符串
data0 = "Hello, World"
# 列表
data1 = list(range(20))[1::2]
# 元组
data2 = ("x", "y", "z")
# 字典
data3 = {'a': data0, 'b':data1, 'c': data2}
print(data0)
print(data1)
print(data2)
print(data3)
output = open('data.pkl', "wb")
# 使用默认的 Protocol
pickle.dump(data0, output)
pickle.dump(data1, output)
pickle.dump(data2, output)
pickle.dump(data3, output)
output.close()上述代码将不同的 Python 对象依次写入文件,并打印对象的相关信息,运行结果如下
1
2
3
4Hello, World
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
('x', 'y', 'z')
{'a': 'Hello, World', 'b': [1, 3, 5, 7, 9, 11, 13, 15, 17, 19], 'c': ('x', 'y', 'z')}反序列化示例(example_deserilization.py)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import pickle
pkl_file = open("data.pkl", 'rb')
data0 = pickle.load(pkl_file)
data1 = pickle.load(pkl_file)
data2 = pickle.load(pkl_file)
data3 = pickle.load(pkl_file)
print(data0)
print(data1)
print(data2)
print(data3)
pkl_file.close()上代码从文件中依次恢复序列化对象,并打印对象的相关信息,运行结果如下
1
2
3
4Hello, World
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
('x', 'y', 'z')
{'a': 'Hello, World', 'b': [1, 3, 5, 7, 9, 11, 13, 15, 17, 19], 'c': ('x', 'y', 'z')}可以看出运行结果与序列化示例运行的结果完全一致。