
这里我们主要学习多进程 multiprocessing 模块的其他类与方法,包括:
- 进程并发控制之 Seamphore
- 进程同步之 Lock
- 进程同步之 Event
- 进程优先级队列 Queue
- 多进程之进程池 Pool
- 多进程之数据交换 Pipe
进程并发控制之 Semaphore
Semaphore 是用来控制对共享资源的访问数量,可以控制同一时间并发的进程数。示例如下:
多进程同步控制
multi_process_semaphore.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import multiprocessing
import time
def worker(s, i):
s.acquire()
print(time.strftime('%H:%M:%S'), multiprocessing.current_process().name + ' 获得锁运行')
time.sleep(i)
print(time.strftime('%H:%M:%S'), multiprocessing.current_process().name + ' 释放锁运行')
s.release()
if __name__ == '__main__':
multiprocessing.set_start_method('fork') # 修改 Python 启动进程的方式为 fork
s = multiprocessing.Semaphore(2) # 设置同一时刻只有2个进程在执行操作
for i in range(6):
p = multiprocessing.Process(target=worker, args=(s, 2))
p.start()注意: 由于 Mac 电脑默认启动进程的方式是 fork, 而 Python 默认的方式是 spawn, 所有需要将 python 启动进程的方式做修改,所以这里使用
multiprocessing.set_start_method('fork')修改了 Python 启动进程的方式为 fork,否则会报如下错误1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/Users/wanwu/.pyenv/versions/3.10.10/lib/python3.10/multiprocessing/spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "/Users/wanwu/.pyenv/versions/3.10.10/lib/python3.10/multiprocessing/spawn.py", line 126, in _main
self = reduction.pickle.load(from_parent)
File "/Users/wanwu/.pyenv/versions/3.10.10/lib/python3.10/multiprocessing/synchronize.py", line 110, in __setstate__
self._semlock = _multiprocessing.SemLock._rebuild(*state)
FileNotFoundError: [Errno 2] No such file or directory
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/Users/wanwu/.pyenv/versions/3.10.10/lib/python3.10/multiprocessing/spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "/Users/wanwu/.pyenv/versions/3.10.10/lib/python3.10/multiprocessing/spawn.py", line 126, in _main
self = reduction.pickle.load(from_parent)
File "/Users/wanwu/.pyenv/versions/3.10.10/lib/python3.10/multiprocessing/synchronize.py", line 110, in __setstate__
self._semlock = _multiprocessing.SemLock._rebuild(*state)
FileNotFoundError: [Errno 2] No such file or directory由于我们设置了
s = multiprocessing.Semaphore(2),因此同一时刻只有两个进程在执行操作,输出如下1
2
3
4
5
6
7
8
9
10
11
1211:01:16 Process-1 获得锁运行
11:01:16 Process-2 获得锁运行
11:01:18 Process-2 释放锁运行
11:01:18 Process-1 释放锁运行
11:01:18 Process-3 获得锁运行
11:01:18 Process-4 获得锁运行
11:01:20 Process-4 释放锁运行
11:01:20 Process-3 释放锁运行
11:01:20 Process-5 获得锁运行
11:01:20 Process-6 获得锁运行
11:01:22 Process-5 释放锁运行
11:01:22 Process-6 释放锁运行
进程同步之 Lock
多进程的目的是并发执行,提高资源利用率,从而提高效率,但有时候我们需要在某一时间只能有一个进程访问某个共享资源,这种情形就需要使用锁 Lock。
示例,多个进程不加锁时输出信息
multi_process_no_lock.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import multiprocessing
import time
def task1():
n = 5
while n > 1:
print(f"{time.strftime('%H:%M:%S')} task1 输出信息")
time.sleep(1)
n -= 1
def task2():
n = 5
while n > 1:
print(f"{time.strftime('%H:%M:%S')} task2 输出信息")
time.sleep(1)
n -= 1
def task3():
n = 5
while n > 1:
print(f"{time.strftime('%H:%M:%S')} task3 输出信息")
time.sleep(1)
n -= 1
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task1)
p2 = multiprocessing.Process(target=task2)
p3 = multiprocessing.Process(target=task3)
p1.start()
p2.start()
p3.start()上述代码未使用锁,生成三个子进程,每个进程都打印自己的信息,运行结果如下
1
2
3
4
5
6
7
8
9
10
11
1211:14:09 task2 输出信息
11:14:09 task1 输出信息
11:14:09 task3 输出信息
11:14:10 task2 输出信息
11:14:10 task1 输出信息
11:14:10 task3 输出信息
11:14:11 task2 输出信息
11:14:11 task1 输出信息
11:14:11 task3 输出信息
11:14:12 task1 输出信息
11:14:12 task2 输出信息
11:14:12 task3 输出信息从运行结果来看,同一时刻有三个进程都在打印信息,在实际的应用中,可能会造成信息混乱。现在我们修改一下上面的程序,要求同一时刻仅有今个进城在输出信息。
示例,多个进程加锁时输出信息
multi_process_lock.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import multiprocessing
import time
def task1(lock):
with lock:
n = 5
while n > 1:
print(f"{time.strftime('%H:%M:%S')} task1 输出信息")
time.sleep(1)
n -= 1
def task2(lock):
lock.acquire()
n = 5
while n > 1:
print(f"{time.strftime('%H:%M:%S')} task2 输出信息")
time.sleep(1)
n -= 1
lock.release()
def task3(lock):
lock.acquire()
n = 5
while n > 1:
print(f"{time.strftime('%H:%M:%S')} task3 输出信息")
time.sleep(1)
n -= 1
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method('fork') # 修改 Python 进程启动方法。Mac 下需要添加该行
lock = multiprocessing.Lock()
p1 = multiprocessing.Process(target=task1, args=(lock,))
p2 = multiprocessing.Process(target=task2, args=(lock,))
p3 = multiprocessing.Process(target=task3, args=(lock,))
p1.start()
p2.start()
p3.start()上面的代码中,每一个子进程任务函数都加了锁 Lock。使用锁也非常简单,首先初始化一个锁的实例
lock = multiprocessing.Lock(),然后在需要独占的代码前后加锁(先获取锁),即调用lock.acquire(),运行完成后释放锁,即调用lock.release();也可以使用上下文关键字with;
上述代码运行结果如下:1
2
3
4
5
6
7
8
9
10
11
1211:25:06 task1 输出信息
11:25:07 task1 输出信息
11:25:08 task1 输出信息
11:25:09 task1 输出信息
11:25:10 task2 输出信息
11:25:11 task2 输出信息
11:25:12 task2 输出信息
11:25:13 task2 输出信息
11:25:14 task3 输出信息
11:25:15 task3 输出信息
11:25:16 task3 输出信息
11:25:17 task3 输出信息从输出可以看出,同一时刻仅有一个进程在输出信息
进程同步之 Event
Event 是用来实现进程之间同步通信,请看下面的例子
示例,
multi_process_event.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import multiprocessing
import time
def wait_for_event(e):
e.wait()
time.sleep(1)
# 唤醒后清除 Event 状态,为后续继续等待
e.clear()
print(f"{time.strftime('%H:%M:%S')} 进程A: 我们是兄弟,我等你 ...")
e.wait()
print(f"{time.strftime('%H:%M:%S')} 进程A: 好的,是兄弟一起走")
def wait_for_event_timeout(e, t):
e.wait()
time.sleep(1)
# 唤醒后清除 Event 状态,为后续继续等待
e.clear()
print(f"{time.strftime('%H:%M:%S')} 进程B: 好吧,最多等你 {t} 秒")
e.wait(t)
print(f"{time.strftime('%H:%M:%S')} 进程B: 我继续往前走了")
if __name__ == '__main__':
e = multiprocessing.Event()
w1 = multiprocessing.Process(target=wait_for_event, args=(e,))
w2 = multiprocessing.Process(target=wait_for_event_timeout, args=(e, 5))
w1.start()
w2.start()
# 主进程发消息
print(f"{time.strftime('%H:%M:%S')} 主进程: 谁等我下,我需要 8s 时间")
# 唤醒等待的进程
e.set()
time.sleep(8)
print(f"{time.strftime('%H:%M:%S')} 主进程: 好了,我赶上了")
# 再次唤醒等待的进程
e.set()
w1.join()
w2.join()
print(f"{time.strftime('%H:%M:%S')} 主进程: 退出")上述代码定义了两个进程函数:一个用于等待事件发生;另一个用于等待事件发生并设置超时时间。主进程调用事件的 set() 方法唤醒等待事件的进程,时间唤醒后调用 clear() 方法清除事件的状态并重新等待,以此达到进程同步的控制。执行结果如下
1
2
3
4
5
6
711:41:09 主进程: 谁等我下,我需要 8s 时间
11:41:10 进程B: 好吧,最多等你 5 秒
11:41:10 进程A: 我们是兄弟,我等你 ...
11:41:15 进程B: 我继续往前走了
11:41:17 主进程: 好了,我赶上了
11:41:17 进程A: 好的,是兄弟一起走
11:41:17 主进程: 退出
进程优先级队列 Queue
Queue 是多进程安全的队列,可以使用 Queue 实现多进程之间的数据传递。
put 方法用以插入数据到队列中,put 方法还有两个可选参数: blocked 和 timeout。
- 如果 blocked 为 True(默认值),并且 timeout 为正值,则该方法会阻塞 timeout 指定的时间,直到该队列有剩余的空间。如果超时,则会抛出
Queue.Full异常。 - 如果 blocked 为 False,但该 Queue 已满,则会立即抛出
Queue.Full异常。
get 方法可以从队列读取并删除一个元素。同样,get 方法有两个可选参数: blocked 和 timeout。
- 如果 blocked 为 True(默认值),并且 timeout 为正值,在等待时间内没有取到任何元素,则会抛出
Queue.Empty异常。 - 如果 blocked 为 False,那么将会有两种情况存在: Queue 有一个值可用,立即返回该值,否则队列为空,立即抛出
Queue.Empty异常。
示例,使用多进程实现生产者-消费者模式
multi_process_queue.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import time
from multiprocessing import Process, Queue
def producerA(q):
count = 1
while True:
q.put(f"冷饮 {count}")
print(f"{time.strftime('%H:%M:%S')} A 放入: [冷饮 {count}]")
count += 1
time.sleep(1)
def consumerB(q):
while True:
print(f"{time.strftime('%H:%M:%S')} B 取出 [{q.get()}]")
time.sleep(5)
if __name__ == '__main__':
q = Queue(maxsize=5)
p = Process(target=producerA, args=(q,))
c = Process(target=consumerB, args=(q,))
c.start()
p.start()
c.join()
p.join()上述代码定义了生产者函数和消费者函数,设置队列的最大容量是 5,生产者不停地生产冷饮,消费者就不停的取出冷饮,当队列满时,生产者等待,当队列空时,消费者等待。它们放入和取出的速度可能不一致,但使用 Queue 可以让生产者和消费者有条不紊地一直处理下去。运行结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1620:09:10 A 放入: [冷饮 1]
20:09:10 B 取出 [冷饮 1]
20:09:11 A 放入: [冷饮 2]
20:09:12 A 放入: [冷饮 3]
20:09:13 A 放入: [冷饮 4]
20:09:14 A 放入: [冷饮 5]
20:09:15 B 取出 [冷饮 2]
20:09:15 A 放入: [冷饮 6]
20:09:16 A 放入: [冷饮 7]
20:09:20 B 取出 [冷饮 3]
20:09:20 A 放入: [冷饮 8]
20:09:25 B 取出 [冷饮 4]
20:09:25 A 放入: [冷饮 9]
20:09:30 B 取出 [冷饮 5]
20:09:30 A 放入: [冷饮 10]
...从结果可以看出,生产者 A 生产的速度比较快,当队列满时,等待消费者 B 取出后继续放入。
多进程之进程池 Pool
当使用 Python 进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机进行操作,可以节约大量的时间。当被操作对象数目不大时,可以直接利用 multiprocessing 中的 Process 动态生成多个进程,十几个还好,但如果是上百个,上千个目标,手动限制进程数量又太过麻烦,此时就可以发挥进程池的功效了。
Pool 可以提供指定数量的进程供用户调用,当有新的请求提交到 Pool 中时,如果池还没有满,就会创建一个新的进程用于执行该请求;如果池中的进程数量已经达到规定的最大值,该请求就会被等待,直到池中有进程结束才会创建新的进程。
示例,多进程使用进程池
multi_process_pool.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import time
import multiprocessing
def task(name):
print(f"{time.strftime('%H:%M:%S')}: {name} 开始执行")
time.sleep(3)
if __name__ == '__main__':
pool = multiprocessing.Pool(processes=3)
for i in range(10):
# 维持执行的进程总数为 processes,当一个进程执行完毕后会添加新的进程进去
pool.apply_async(func=task, args=(i,))
pool.close()
pool.join()
print("hello")运行结果如下
1
2
3
4
5
6
7
8
9
10
1120:20:45: 0 开始执行
20:20:45: 1 开始执行
20:20:45: 2 开始执行
20:20:48: 3 开始执行
20:20:48: 4 开始执行
20:20:48: 5 开始执行
20:20:51: 6 开始执行
20:20:51: 7 开始执行
20:20:51: 8 开始执行
20:20:54: 9 开始执行
hello从运行结果来看同一时刻只有三个进程在执行,使用 Pool 实现了对进程并发数量的控制
多进程之数据交换 Pipe
我们在 类 Unix 系统中经常使用管道(Pipe) 命令来让一条命令的输出作为另一条命令的输入获取最终的结果。在 Python 多进程编程中也有一个 Pipe 方法可以帮我们实现多进程之前的数据传入。我们可以将 Unix 系统的一个命令比作一个进程,一个进程的输出可以作为另一个进程是输入。如下如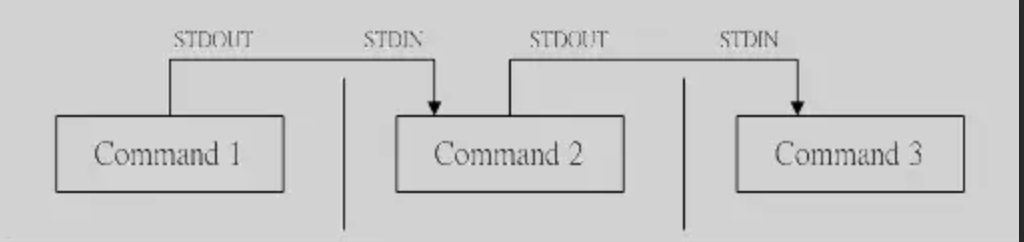
multiprocessing.Pipe() 方法返回一个管道的两个端口,如 Command1 的 STDOUT 和 Command2 的 STDIN,这样 Command1 的输出就作为 Command2的输入。如果反过来,让 Command2 的输出也可以作为 Command1 的输入,这就是全双工管道,默认全双工通道。如果想设置半双工管道,只需要给 Pipe() 方法传递参数 duplex=False 就可以,即 Pipe(dulex=False)。
Pipe() 方法返回的对象具有发送消息 send() 方法和接收消息 recv() 方法,可以调用 Command1.send(msg) 发送消息,调用 Command2.recv() 接收消息。如果没有消息可接收,revc() 方法会一直阻塞。如果管道已经被关闭,recv() 方法就会抛出异常 EOFError。
示例,多进程全双工管道
multi_process_pipe.py11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import multiprocessing
import time
def task1(pipe):
for i in range(5):
string = f"task-{i}"
print(f"{time.strftime('%H:%M:%S')} task1 发送: {string}")
pipe.send(string)
time.sleep(2)
for i in range(5):
print(f"{time.strftime('%H:%M:%S')} task1 接收: {pipe.recv()}")
def task2(pipe):
for i in range(5):
print(f"{time.strftime('%H:%M:%S')} task2 接收: {pipe.recv()}")
time.sleep(1)
for i in range(5):
string = f"task2-{i}"
print(f"{time.strftime('%H:%M:%S')} task2 发送: {string}")
pipe.send(string)
if __name__ == '__main__':
pipe = multiprocessing.Pipe()
p1 = multiprocessing.Process(target=task1, args=(pipe[0],))
p2 = multiprocessing.Process(target=task2, args=(pipe[1],))
p1.start()
p2.start()
p1.join()
p2.join()首先程序定义了两个子进程函数: task1 先发送 5 条信息,再接收消息;task2 先接收消息,再发送消息,运行结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2020:46:19 task1 发送: task-0
20:46:19 task1 发送: task-1
20:46:19 task1 发送: task-2
20:46:19 task1 发送: task-3
20:46:19 task1 发送: task-4
20:46:19 task2 接收: task-0
20:46:19 task2 接收: task-1
20:46:19 task2 接收: task-2
20:46:19 task2 接收: task-3
20:46:19 task2 接收: task-4
20:46:20 task2 发送: task2-0
20:46:20 task2 发送: task2-1
20:46:20 task2 发送: task2-2
20:46:20 task2 发送: task2-3
20:46:20 task2 发送: task2-4
20:46:21 task1 接收: task2-0
20:46:21 task1 接收: task2-1
20:46:21 task1 接收: task2-2
20:46:21 task1 接收: task2-3
20:46:21 task1 接收: task2-4注意: 代码中的 time.sleep() 可以让显示的结果不会太混乱,这一步并不会影响进程接收和发送消息