
官方文档地址: Ceph Storage
安装 Rook
注意事项:
- 做这个实验需要高配置,k8s 集群最少5个节点,每个节点配置不能低于2核4G,至少有3个存储节点;
- rook的版本大于1.3,不能使用目录创建集群,要使用单独的裸盘进行创建,也就是创建一个新的磁盘,挂载到宿主机,不进行格式化,直接使用即可;
- k8s 1.19以上版本,快照功能需要单独安装snapshot控制器;
- 使用的是 K8s 1.15 或更早版本,则需要创建不同版本的 Rook CRD。创建在示例清单的 pre-k8s-1.16 子文件夹中找到的 crds.yaml;
- k8s 集群所有的节点时间必须一致,不能存在任何的污点,如果存在污点,可能会导致 pod 一致处于 Pending 状态。
可以使用以下命令检查磁盘是否已被格式化文件系统,如下所示,如果 FSTYPE 字段不为空,则说明该设备已被格式化为文件系统,这种设备不能用于 Ceph,像下面的 sdb 设备可以用于 Ceph。
1
2
3
4
5
6
7
8
9[root@k8s-node-01 ~]# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sdb
sr0 iso9660 CentOS 7 x86_64 2020-11-04-11-36-43-00
sda
├─sda2 LVM2_member UXWn6l-7QU7-kBya-8MRo-Uj8n-Ix2V-lWN8d2
│ ├─centos-swap swap af978619-8f0c-45bb-b6c8-c2e5aae46567
│ └─centos-root xfs 49b57240-d9f2-43cb-b726-ed6e8f376f70 /
└─sda1 xfs 89028509-fc97-47cb-b838-1cb7115bd325 /boot检查节点是否存在污点
1
2
3
4
5
6# kubectl describe nodes |grep Taint
Taints: <none>
Taints: <none>
Taints: <none>
Taints: <none>
Taints: <none>
下载 rook 安装文件
下载指定版本Rook
1
git clone --single-branch --branch v1.7.2 https://github.com/rook/rook.git
更改 operator 配置
修改 Rook CSI 镜像地址,原本的地址可能是 gcr 的镜像,但是 gcr 的镜像无法被国内访问,所以需要同步 gcr 的镜像到阿里云镜像仓库。进入
rook/cluster/examples/kubernetes/ceph目录,修改operator.yaml文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 需要修改的地方如下所示
# ROOK_CSI_CEPH_IMAGE: "quay.io/cephcsi/cephcsi:v3.4.0"
# ROOK_CSI_REGISTRAR_IMAGE: "k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.2.0"
# ROOK_CSI_RESIZER_IMAGE: "k8s.gcr.io/sig-storage/csi-resizer:v1.2.0"
# ROOK_CSI_PROVISIONER_IMAGE: "k8s.gcr.io/sig-storage/csi-provisioner:v2.2.2"
# ROOK_CSI_SNAPSHOTTER_IMAGE: "k8s.gcr.io/sig-storage/csi-snapshotter:v4.1.1"
# ROOK_CSI_ATTACHER_IMAGE: "k8s.gcr.io/sig-storage/csi-attacher:v3.2.1"
# 将注释取消,然后修改镜像地址为以下地址,记得要与上面的 ROOK_CSI_ALLOW_UNSUPPORTED_VERSION: "false" 缩进对其
ROOK_CSI_CEPH_IMAGE: "registry.cn-hangzhou.aliyuncs.com/59izt/cephcsi:v3.4.0"
ROOK_CSI_REGISTRAR_IMAGE: "registry.cn-hangzhou.aliyuncs.com/59izt/csi-node-driver-registrar:v2.2.0"
ROOK_CSI_RESIZER_IMAGE: "registry.cn-hangzhou.aliyuncs.com/59izt/csi-resizer:v1.2.0"
ROOK_CSI_PROVISIONER_IMAGE: "registry.cn-hangzhou.aliyuncs.com/59izt/csi-provisioner:v2.2.2"
ROOK_CSI_SNAPSHOTTER_IMAGE: "registry.cn-hangzhou.aliyuncs.com/59izt/csi-snapshotter:v4.1.1"
ROOK_CSI_ATTACHER_IMAGE: "registry.cn-hangzhou.aliyuncs.com/59izt/csi-attacher:v3.2.1"新版本 rook 默认关闭了自动发现容器的部署,可以找到
ROOK_ENABLE_DISCOVERY_DAEMON改成 true 即可1
2
3# Whether to start the discovery daemon to watch for raw storage devices on nodes in the cluster.
# This daemon does not need to run if you are only going to create your OSDs based on StorageClassDeviceSets with PVCs.
ROOK_ENABLE_DISCOVERY_DAEMON: "true"
部署 rook
进入
rook/cluster/examples/kubernetes/ceph/目录,执行以下命令,等待 operator 容器和 discover 容器启动1
2cd rook/cluster/examples/kubernetes/ceph/
kubectl create -f crds.yaml -f common.yaml -f operator.yaml查看 Pod 状态
1
2
3
4
5
6
7
8# kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-5f78fffd97-2cr7x 1/1 Running 0 7m50s
rook-discover-47cqp 1/1 Running 0 6m13s
rook-discover-6pdz7 1/1 Running 0 6m13s
rook-discover-mn9q2 1/1 Running 0 6m13s
rook-discover-t7tzf 1/1 Running 0 6m13s
rook-discover-zxlk6 1/1 Running 0 6m13s全部变成1/1 Running 才可以创建Ceph集群
部署 Ceph 集群
修改 cluster 配置
进入 rook/cluster/examples/kubernetes/ceph/ 目录,修改 cluster.yaml 文件,需要修改的地方如下:
修改 ceph 镜像地址为阿里云地址
1
image: registry.cn-hangzhou.aliyuncs.com/59izt/ceph:v16.2.5
spec.skipUpgradeChecks: 是否跳过更新检查,更改为truespec.mon.count: mons 节点数,不能低于3spec.mon.allowMultiplePerNode: 是否允许多个 mons 部署在同一个节点,为了高可用性,这里设置为falsespec.mgr.count: mgr 的节点数,生产环境为了高可用,建议设置为2spec.dashboard.ssl: 生产环境为了方便域名访问,可以设置为falsespec.monitoring: 是否启用 Prometheus 监控指标,如果无法进入 osd 容器创建环节,建议更改为 false;spec.storage.useAllNodes: 是否使用所有节点安装 ceph 集群,这里设置为falsespec.storage.useAllDevices: 是否使用节点上所有的设备作为 osd,这里也设置为falsespec.storage.nodes: 这里设置选择安装 ceph 集群的节点,默认配置被注释了,需要取消注释,然后修改相应内容。如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16...
storage:
useAllNodes: false
useAllDevices: false
config:
nodes:
- name: "k8s-master-03" # 这里必须设置为节点 kubernetes.io/hostname 标签的值
devices:
- name: "sdb"
- name: "k8s-node-01"
devices:
- name: "sdb"
- name: "k8s-node-02"
devices:
- name: "sdb"
...
部署 ceph 集群
创建 ceph 集群
1
kubectl create -f cluster.yaml
查看 ceph 集群信息
1
2
3# kubectl get cephcluster -n rook-ceph
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL
rook-ceph /var/lib/rook 3 11h Ready Cluster created successfully HEALTH_WARN查看 ceph 集群相关的 Pod
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-45mtb 3/3 Running 0 11h
csi-cephfsplugin-b6zkh 3/3 Running 0 11h
csi-cephfsplugin-pngrj 3/3 Running 0 11h
csi-cephfsplugin-provisioner-5cc755d98-p8x4k 6/6 Running 0 11h
csi-cephfsplugin-provisioner-5cc755d98-wr5ww 6/6 Running 0 11h
csi-cephfsplugin-tbmhs 3/3 Running 0 11h
csi-cephfsplugin-vdqgz 3/3 Running 0 11h
csi-rbdplugin-5lscr 3/3 Running 0 11h
csi-rbdplugin-f82ll 3/3 Running 0 11h
csi-rbdplugin-lcz95 3/3 Running 0 11h
csi-rbdplugin-lqj6h 3/3 Running 0 11h
csi-rbdplugin-provisioner-7f9d994dfc-h8q88 6/6 Running 0 11h
csi-rbdplugin-provisioner-7f9d994dfc-phrg7 6/6 Running 0 11h
csi-rbdplugin-vpv7m 3/3 Running 0 11h
rook-ceph-crashcollector-k8s-master-02-f467cff87-j44wq 1/1 Running 0 11h
rook-ceph-crashcollector-k8s-master-03-64d9fbb6d4-q77ng 1/1 Running 0 11h
rook-ceph-crashcollector-k8s-node-01-55b86cf44-7qvc8 1/1 Running 0 11h
rook-ceph-crashcollector-k8s-node-02-5c96b778cc-fbjdd 1/1 Running 0 11h
rook-ceph-mgr-a-76c94657bb-qqtnf 1/1 Running 0 11h
rook-ceph-mon-a-d9865c59-trhzc 1/1 Running 1 (3h7m ago) 11h
rook-ceph-mon-b-75d45c944-b47fm 1/1 Running 0 11h
rook-ceph-mon-c-6479cdc7f-m2f62 1/1 Running 0 11h
rook-ceph-operator-5f78fffd97-2cr7x 1/1 Running 2 (13h ago) 24h
rook-ceph-osd-0-9fc9b59b7-r8gkn 1/1 Running 0 11h
rook-ceph-osd-1-59c46b5b86-kzm7q 1/1 Running 0 11h
rook-ceph-osd-2-6c464945bc-cbdn9 1/1 Running 0 11h
rook-ceph-osd-prepare-k8s-master-03--1-wtwjj 0/1 Completed 0 47m
rook-ceph-osd-prepare-k8s-node-01--1-vv525 0/1 Completed 0 47m
rook-ceph-osd-prepare-k8s-node-02--1-qsvsh 0/1 Completed 0 47m
rook-discover-47cqp 1/1 Running 1 (13h ago) 24h
rook-discover-6pdz7 1/1 Running 2 (13h ago) 24h
rook-discover-mn9q2 1/1 Running 1 (13h ago) 24h
rook-discover-t7tzf 1/1 Running 1 (13h ago) 24h
rook-discover-zxlk6 1/1 Running 1 (13h ago) 24h
安装 Ceph 客户端工具
要验证集群是否处于健康状态,需要连接到 Rook 工具箱并运行 ceph status 命令。
安装 ceph 客户端工具
1
2# kubectl create -f toolbox.yaml -n rook-ceph
deployment.apps/rook-ceph-tools created等容器进入 running 状态后,既可执行相关命令
1
2
3# kubectl get pods -n rook-ceph -l app=rook-ceph-tools
NAME READY STATUS RESTARTS AGE
rook-ceph-tools-6b795cd9f5-2tpvl 1/1 Running 0 7h59m验证 ceph 集群的健康状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# kubectl exec -i -t -n rook-ceph rook-ceph-tools-6b795cd9f5-2tpvl -- ceph status
cluster:
id: a76fccd2-2750-4754-b3e4-9b43479f43e4
health: HEALTH_WARN
clock skew detected on mon.b
services:
mon: 3 daemons, quorum a,b,c (age 11h)
mgr: a(active, since 11h)
osd: 3 osds: 3 up (since 11h), 3 in (since 11h)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 15 MiB used, 60 GiB / 60 GiB avail
pgs: 1 active+clean
# kubectl exec -i -t -n rook-ceph rook-ceph-tools-6b795cd9f5-2tpvl -- ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 k8s-node-01 5272k 19.9G 0 0 0 0 exists,up
1 k8s-master-03 5272k 19.9G 0 0 0 0 exists,up
2 k8s-node-02 5272k 19.9G 0 0 0 0 exists,up
# kubectl exec -i -t -n rook-ceph rook-ceph-tools-6b795cd9f5-2tpvl -- ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 60 GiB 60 GiB 15 MiB 15 MiB 0.03
TOTAL 60 GiB 60 GiB 15 MiB 15 MiB 0.03
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 19 GiB
部署 Ceph Dashboard
默认情况下,ceph dashboard 是打开的,但是使用的是 ClusterIP。要想外部访问 Dashboard, 可以创建一个 nodePort 类型的Service暴露服务
创建 ceph-dashboard-np.yaml,可以使用以下命令获取默认的 yaml 文件,然后进行修改该配置文件
1
kubectl get svc -n rook-ceph rook-ceph-mgr-dashboard -oyaml > ceph-dashboard-np.yaml
调整好后的 ceph-dashboard-np.yaml 文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22apiVersion: v1
kind: Service
metadata:
labels:
app: rook-ceph-mgr
ceph_daemon_id: a
rook_cluster: rook-ceph
name: rook-ceph-mgr-dashboard-np
namespace: rook-ceph
spec:
ports:
- name: http-dashboard
port: 7000
protocol: TCP
targetPort: 7000
nodePort: 30010
selector:
app: rook-ceph-mgr
ceph_daemon_id: a
rook_cluster: rook-ceph
sessionAffinity: None
type: NodePort创建 Dashboard 资源
1
2# kubectl create -f ceph-dashboard-np.yaml
service/rook-ceph-mgr-dashboard-np created查看新建的 svc
1
2
3
4
5# kubectl get svc -n rook-ceph --show-labels -l app=rook-ceph-mgr
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
rook-ceph-mgr ClusterIP 10.100.224.205 <none> 9283/TCP 3h25m app=rook-ceph-mgr,ceph_daemon_id=a,rook_cluster=rook-ceph
rook-ceph-mgr-dashboard ClusterIP 10.100.161.92 <none> 7000/TCP 3h25m app=rook-ceph-mgr,ceph_daemon_id=a,rook_cluster=rook-ceph
rook-ceph-mgr-dashboard-np NodePort 10.108.135.55 <none> 7000:30010/TCP 76s app=rook-ceph-mgr,ceph_daemon_id=a,rook_cluster=rook-ceph打开浏览器,通过任意k8s节点的IP+ 30010 即可访问该dashboard

输入用户名和密码,默认用户名为
admin,密码可以使用以下命令查看1
2# kubectl get secrets -n rook-ceph rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" |base64 --decode && echo
h}Jf;{R[/`Zo/29R,\{-ceph web 管理界面如下图所示:
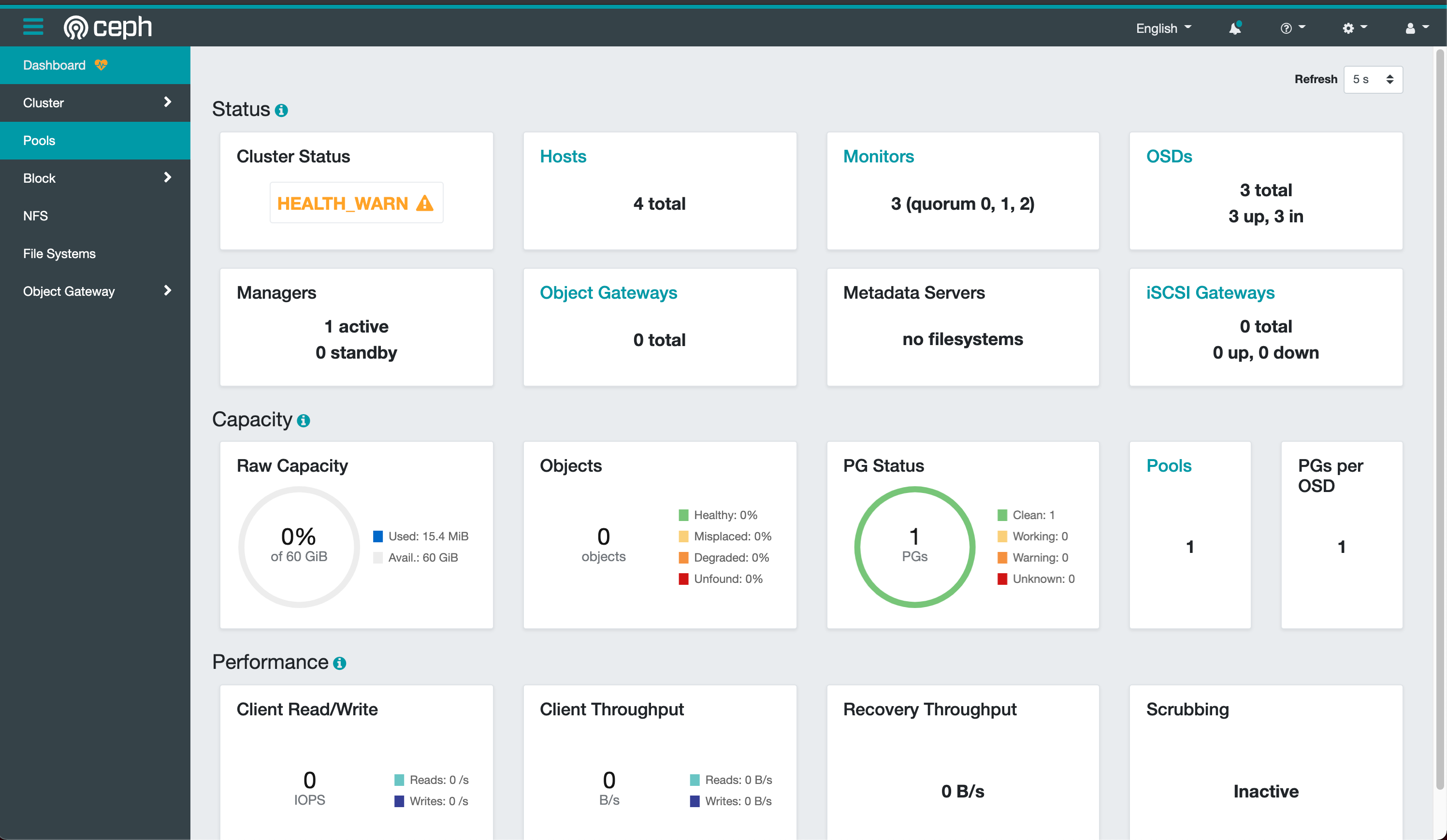
告警解决方法: HEALTH CHECKS
Rook-Ceph mon 时钟误差的问题解决
- 编辑 Rook 的 configmaps 配置
rook-config-override,添加相应参数,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14# kubectl edit configmaps -n rook-ceph rook-config-override
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
config: |
[global]
mon clock drift allowed = 2
mon data avail warn = 20
kind: ConfigMap
...- 删除相关的 Pod,然后系统会自动拉起新的 Pod,更新配置
1
2
3
4# kubectl delete pods -n rook-ceph $(kubectl get pods -n rook-ceph -o custom-columns=NAME:.metadata.name --no-headers | grep mon)
pod "rook-ceph-mon-a-68846769d6-kx6q5" deleted
pod "rook-ceph-mon-b-76bc5c54d5-fgs5j" deleted
pod "rook-ceph-mon-c-6644fbb9b4-kcx7h" deleted- 再次查看健康状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# kubectl exec -i -t -n rook-ceph rook-ceph-tools-6b795cd9f5-q5w29 -- ceph status
cluster:
id: cba2518a-5e46-4d57-bd4f-4ec11c73de03
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 6m)
mgr: a(active, since 37m)
osd: 3 osds: 3 up (since 37m), 3 in (since 37m)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 15 MiB used, 60 GiB / 60 GiB avail
pgs: 1 active+clean- 编辑 Rook 的 configmaps 配置