
- Golang 官方文档: golang.google.cn
- C 语言中文网: Golang 简介
Go 语言的变量逃逸分析
在讨论变量生命周期之前,先来了解下计算机组成里两个非常重要的概念:堆和栈。
什么是栈
栈(Stack)是一种拥有特殊规则的线性表数据结构。
概念
栈只允许从线性表的同一端放入和取出数据,按照后进先出(LIFO,Last In First Out)的顺序,如下图所示: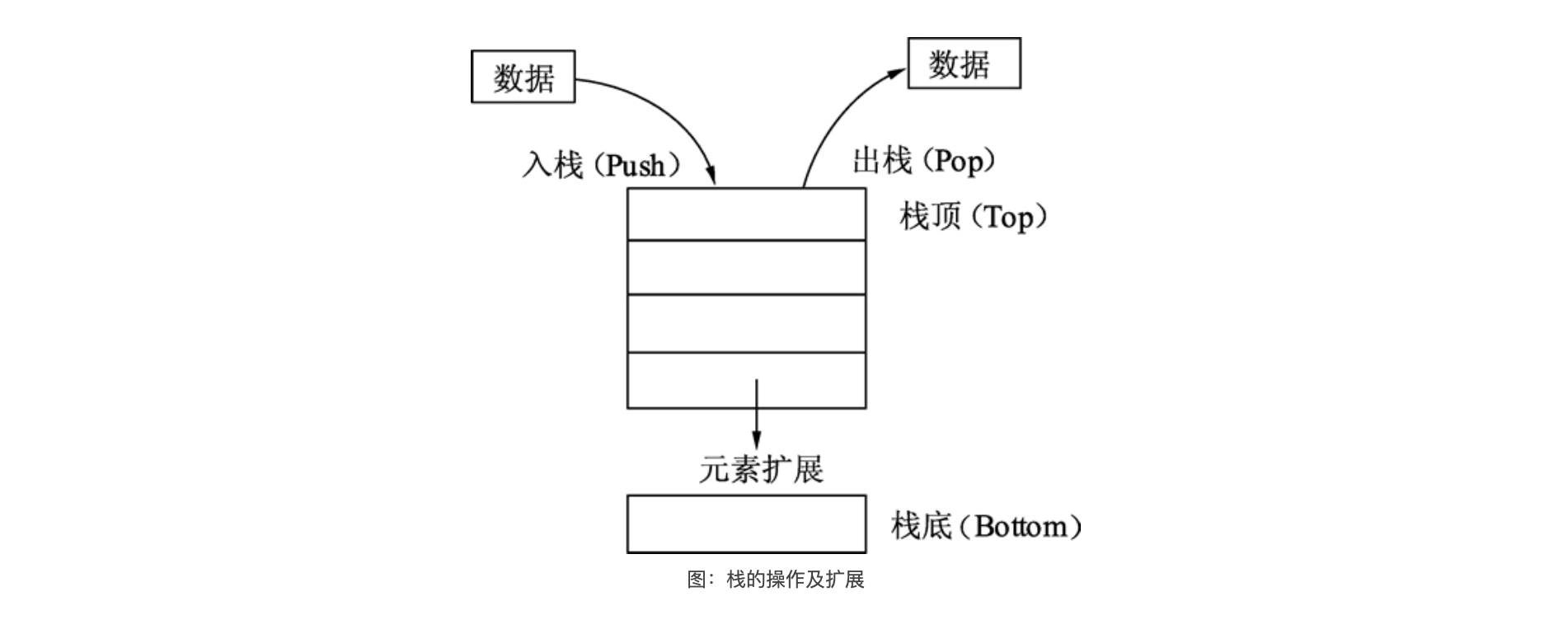
往栈中放入元素的过程叫做入栈。入栈会增加栈的元素数量,最后放入的元素总是位于栈的顶部,最先放入的元素总是位于栈的底部。
从栈中取出元素时,只能从栈顶部取出。取出元素后,栈的元素数量会变少。最先放入的元素总是最后被取出,最后放入的元素总是最先被取出。不允许从栈底获取数据,也不允许对栈成员(除了栈顶部的成员)进行任何查看和修改操作。
栈的原理类似于将书籍一本一本地堆起来。书按顺序一本一本从顶部放入,要取书时只能从顶部一本一本取出。
变量和栈有什么关系
栈可用于内存分配,栈的分配和回收速度非常快。
下面的代码展示了栈在内存分配上的作用
1
2
3
4
5
6
7
8
9func calc(a, b int) int {
var c int
c = a * b
var x int
x = c * 10
return x
}代码说明
- 第 1 行,传入 a、b 两个整型参数。
- 第 2 行,声明整型变量 c,运行时,c 会分配一段内存用以存储 c 的数值。
- 第 3 行,将 a 和 b 相乘后赋值给 c。
- 第 5 行,声明整型变量 x,x 也会被分配一段内存。
- 第 6 行,让 c 乘以 10 后赋值给变量 x。
- 第 8 行,返回 x 的值。
上面的代码在没有任何优化的情况下,会进行变量 c 和 x 的分配过程。Go语言默认情况下会将 c 和 x 分配在栈上,这两个变量在 calc() 函数退出时就不再使用,函数结束时,保存 c 和 x 的栈内存再出栈释放内存,整个分配内存的过程通过栈的分配和回收都会非常迅速。
什么是堆
堆在内存分配中类似于往一个房间里摆放各种家具,家具的尺寸有大有小,分配内存时,需要找一块足够装下家具的空间再摆放家具。经过反复摆放和腾空家具后,房间里的空间会变得乱七八糟,此时再往这个空间里摆放家具会发现虽然有足够的空间,但各个空间分布在不同的区域,没有一段连续的空间来摆放家具。此时,内存分配器就需要对这些空间进行调整优化,如下图所示。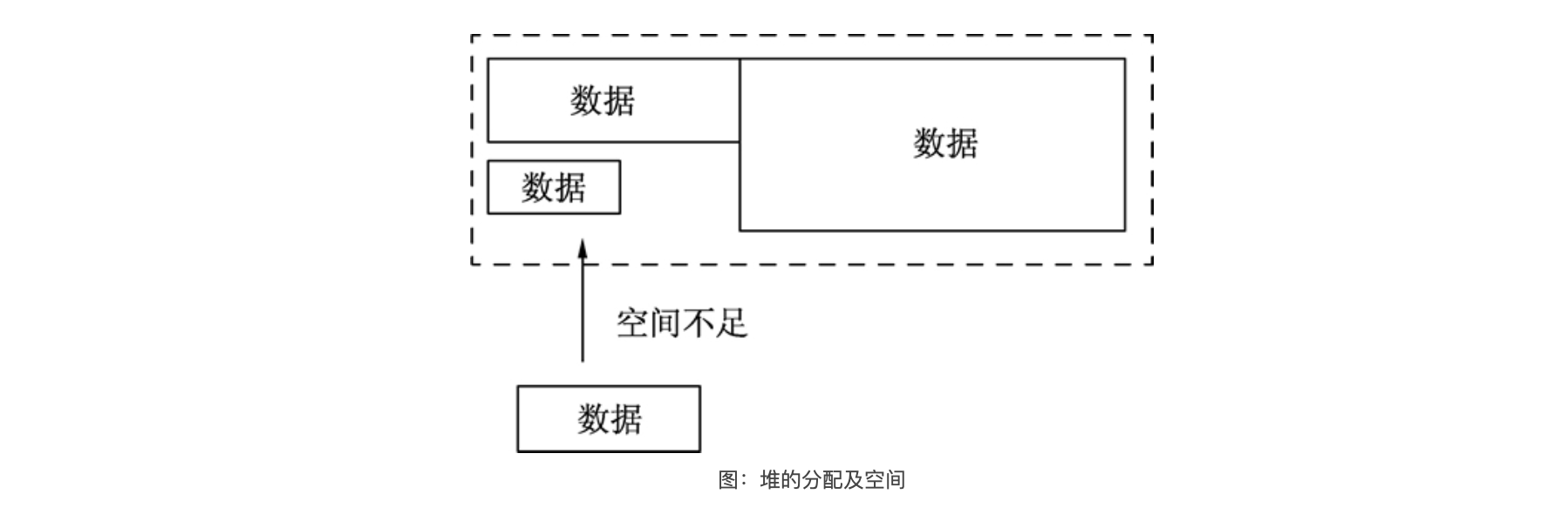
堆分配内存和栈分配内存相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。
变量逃逸 – 自动决定变量分配方式,提高运行效率
堆和栈各有优缺点,该怎么在编程中处理这个问题呢?在 C/C++ 语言中,需要开发者自己学习如何进行内存分配,选用怎样的内存分配方式来适应不同的算法需求。比如,函数局部变量尽量使用栈,全局变量、结构体成员使用堆分配等。程序员不得不花费很长的时间在不同的项目中学习、记忆这些概念并加以实践和使用。
Go语言将这个过程整合到了编译器中,命名为 变量逃逸分析。通过编译器分析代码的特征和代码的生命周期,决定应该使用堆还是栈来进行内存分配。
逃逸分析
通过下面的代码来展现 Go 语言如何使用命令行来分析变量逃逸,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32package main
import (
"fmt"
)
func dummp(b int) int {
// 声明一个变量 c 并赋值
var c int
c = b
return c
}
// 空函数,什么也不做
func void() {
}
func main() {
// 声明变量 a 并打印
var a int
// 调用 void() 函数
void()
// 打印 a 变量的值和 dummp() 函数返回
fmt.Println(a, dummp(0))
}代码说明
- 第 6 行,dummy() 函数拥有一个参数,返回一个整型值,用来测试函数参数和返回值分析情况。
- 第 9 行,声明变量 c,用于演示函数临时变量通过函数返回值返回后的情况。
- 第 16 行,这是一个空函数,测试没有任何参数函数的分析情况。
- 第 23 行,在 main() 中声明变量 a,测试 main() 中变量的分析情况。
- 第 26 行,调用 void() 函数,没有返回值,测试 void() 调用后的分析情况。
- 第 29 行,打印 a 和 dummy(0) 的返回值,测试函数返回值没有变量接收时的分析情况。
使用下面的命令运行上面的代码
1
2
3
4
5
6bash-3.2$ go run -gcflags "-m -l" man.go
# command-line-arguments
./man.go:30:13: ... argument does not escape
./man.go:30:13: a escapes to heap
./man.go:30:22: dummp(0) escapes to heap
0 0程序运行结果分析如下:
- 第 2 行,这句提示是默认的,可以忽略
- 第 3 行,告知代码的第 30 行的变量 a 逃逸到堆
- 第 4 行,告知 “dummy(0) 调用逃逸到堆”。由于 dummy() 函数会返回一个整型值,这个值被 fmt.Println 使用后还是会在 main() 函数中继续存在。
上面例子中变量 c 是整型,其值通过 dummy() 的返回值“逃出”了 dummy() 函数。变量 c 的值被赋值并作为 dummy() 函数的返回值返回,即使变量 c 在 dummy() 函数中分配的内存被释放,也不会影响 main() 中使用 dummy() 返回的值。变量 c 使用栈分配不会影响结果。
取地址发生逃逸
下面的例子使用结构体做数据,来了解结构体在堆上的分配情况,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22package main
import (
"fmt"
)
// 声明空结构体测试结构体逃逸情况
type Data struct {
}
func dummy() *Data {
// 实例化 c 为 Data 类型
var c Data
// 返回函数局部变量地址
return &c
}
func main() {
fmt.Println(dummy())
}代码说明
- 第 6 行,声明一个空的结构体做结构体逃逸分析。
- 第 9 行,将 dummy() 函数的返回值修改为 *Data 指针类型。
- 第 11 行,将变量 c 声明为 Data 类型,此时 c 的结构体为值类型。
- 第 14 行,取函数局部变量 c 的地址并返回。
- 第 18 行,打印 dummy() 函数的返回值。
执行逃逸分析
1
2
3
4
5bash-3.2$ go run -gcflags "-m -l" man.go
# command-line-arguments
./man.go:13:6: moved to heap: c
./man.go:20:13: ... argument does not escape
&{}注意第 2 行出现了新的提示:将 c 移到堆中。这句话表示,Go 编译器已经确认如果将变量 c 分配在栈上是无法保证程序最终结果的,如果这样做,dummy() 函数的返回值将是一个不可预知的内存地址,这种情况一般是 C/C++ 语言中容易犯错的地方,引用了一个函数局部变量的地址。
Go语言最终选择将 c 的 Data 结构分配在堆上。然后由垃圾回收器去回收 c 的内存。
原则
在使用Go语言进行编程时,Go语言的设计者不希望开发者将精力放在内存应该分配在栈还是堆的问题上,编译器会自动帮助开发者完成这个纠结的选择,但变量逃逸分析也是需要了解的一个编译器技术,这个技术不仅用于Go语言,在 Java 等语言的编译器优化上也使用了类似的技术。
编译器觉得变量应该分配在堆和栈上的原则是:
- 变量是否被取地址;
- 变量是否发生逃逸。
变量的生命周期
变量的生命周期指的是在程序运行期间变量有效存在的时间间隔。
变量的生命周期与变量的作用域有着不可分割的联系:
- 全局变量:它的生命周期和整个程序的运行周期是一致的;
- 局部变量:它的生命周期则是动态的,从创建这个变量的声明语句开始,到这个变量不再被引用为止;
- 形式参数和函数返回值:它们都属于局部变量,在函数被调用的时候创建,函数调用结束后被销毁。
下面代码中,在每次循环的开始会创建临时变量 t,然后在每次循环迭代中创建临时变量 x 和 y。临时变量 x、y 存放在栈中,随着函数执行结束(执行遇到最后一个}),释放其内存。
1
2
3
4
5
6
7
8for t := 0.0; t < cycles * 2 * math.Pi; t += res {
x := math.Sin(t)
y := math.Sin(t * freq + phase)
img.SetColorIndex(
size + int(x * size + 0.5), size + int(y * size + 0.5),
blackIndex, // 最后插入的逗号不会导致编译错误,这是Go编译器的一个特性
) // 小括号另起一行缩进,和大括号的风格保持一致
}
栈的概念在 变量逃逸 中介绍过,它和堆的区别在于:
- 堆(heap):堆是用于存放进程执行中被动态分配的内存段。它的大小并不固定,可动态扩张或缩减。当进程调用 malloc 等函数分配内存时,新分配的内存就被动态加入到堆上(堆被扩张)。当利用 free 等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减);
- 栈(stack):栈又称堆栈, 用来存放程序暂时创建的局部变量,也就是我们函数的大括号
{ }中定义的局部变量。
在程序的编译阶段,编译器会根据实际情况自动选择在栈或者堆上分配局部变量的存储空间,不论使用 var 还是 new 关键字声明变量都不会影响编译器的选择。
1 | var global *int |
上述代码中,函数 f 里的变量 x 必须在堆上分配,因为它在函数退出后依然可以通过包一级的 global 变量找到,虽然它是在函数内部定义的。用Go语言的术语说,这个局部变量 x 从函数 f 中逃逸了。
相反,当函数 g 返回时,变量 y 不再被使用,也就是说可以马上被回收的。因此,y 并没有从函数 g 中逃逸,编译器可以选择在栈上分配 *y 的存储空间,也可以选择在堆上分配,然后由Go语言的 GC(垃圾回收机制)回收这个变量的内存空间。
在实际的开发中,并不需要刻意的实现变量的逃逸行为,因为逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。
虽然Go语言能够帮助我们完成对内存的分配和释放,但是为了能够开发出高性能的应用我们任然需要了解变量的生命周期。例如,如果将局部变量赋值给全局变量,将会阻止 GC 对这个局部变量的回收,导致不必要的内存占用,从而影响程序的性能。