
- Golang 官方文档: golang.google.cn
- C 语言中文网: Golang 简介
Go 数据类型
整型
golang 的数值类型分为以下几种:整数、浮点数、复数,其中每一种都包含了不同大小的数值类型,例如有符号整数包含 int8、int16、int32、int64 等,每种数值类型都决定了对应的大小范围和是否支持正负符号。
golang 同时提供了有符号和无符号的整数类型,其中包括 int8、int16、int32 和 int64 四种大小截然不同的有符号整数类型,分别对应 8、16、32、64bit 大小的有符号整数,榆次对应的是 uint8、uint16、uint32 和 uint64 四种无符号整数类型。
此外还有两种整数类型 int 和 uint,它们分别对应特定 CPU 平台的字长(机器字大小),其中 int 代表有符号整数,应用最为广泛,unit 表示无符号整数。实际开发中由于编译器和计算机硬件的不同,int 和 uint 所能表示的整数大小会在 32bit 和 64bit 之间变化。
大多数情况下,我们只需要 int 一种整型即可,它可以用于循环计数器(for 循环中控制循环次数的变量)、数组和切片的索引,以及任何通用目的的整型运算符,通常 int 类型的处理速度也是最快的。
用来表示 Unicode 字符的 rune 类型和 int32 类型是等价的,通常用于表示一个 Unicode 码点。这两个名称可以互换使用。同样,byte 和 uint8 也是等价类型,byte 类型一般用于强调数值是一个原始的数据而不是一个小的整数。
最后,还有一种无符号的整数类型 uintptr,它没有指定具体的 bit 大小但是足以容纳指针。uintptr 类型只有在底层编程时才需要,特别是Go语言和C语言函数库或操作系统接口相交互的地方。
尽管在某些特定的运行环境下 int、uint 和 uintptr 的大小可能相等,但是它们依然是不同的类型,比如 int 和 int32,虽然 int 类型的大小也可能是 32 bit,但是在需要把 int 类型当做 int32 类型使用的时候必须显示的对类型进行转换,反之亦然。
golang 中有符号整数采用 2 的补码形式表示,也就是最高 bit 位用来表示符号位,一个 n-bit 的有符号数的取值范围是从 -2^(n-1)^ 到 2^(n-1)^-1。无符号整数的所有 bit 位都用于表示非负数,取值范围是 0 到 2^n^-1。例如,int8 类型整数的取值范围是从 -128 到 127,而 uint8 类型整数的取值范围是从 0 到 255。
哪些情况下使用 int 和 uint
程序逻辑对整型范围没有特殊需求。例如,对象的长度使用内建 len() 函数返回,这个长度可以根据不同平台的字节长度进行变化。实际使用中,切片或 map 的元素数量等都可以用 int 来表示。
反之,在二进制传输、读写文件的结构描述时,为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用 int 和 uint。
浮点类型
golang 提供了两种精度的浮点数 float32 和 float64,它们的算术规范由 IEEE754 浮点数国际标准定义,该浮点数规范被所有现代的 CPU 支持。
这些浮点数类型的取值范围可以从很微小到很巨大。浮点数取值范围的极限值可以在 math 包中找到:
- 常量 math.MaxFloat32 表示 float32 能取到的最大数值,大约是 3.4e38;
- 常量 math.MaxFloat64 表示 float64 能取到的最大数值,大约是 1.8e308;
- float32 和 float64 能表示的最小值分别为 1.4e-45 和 4.9e-324
一个 float32 类型的浮点数可以提供大约 6 个十进制数的精度,而 float64 则可以提供约 15 个十进制数的精度,通常应该优先使用 float64 类型,因为 float32 类型的累计计算误差很容易扩散,并且 float32 能精确表示的正整数并不是很大。
1 | var f float32 = 16777216 // 1 << 24 |
浮点数在声明的时候可以只写整数部分或者小数部分,像下面这样:
1 | const e = .71828 // 0.71828 |
很小或很大的数最好用科学计数法书写,通过 e 或 E 来指定指数部分:
1 | const Avogadro = 6.02214129e23 // 阿伏伽德罗常数 |
用 Printf 函数打印浮点数时可以使用 %f 来控制保留几位小数
1 | package main |
运行结果如下
1 | 3.141593 |
复数
在计算机中,复数是由两个浮点数表示的,其中一个表示实部(real),一个表示虚部(imag)。
golang 中复数的类型有两种,分别是 complex128(64 位实数和虚数)和 complex64(32 位实数和虚数),其中 complex128 为复数的默认类
型。
复数的值由三部分组成 RE + IMi,其中 RE 是实数部分,IM 是虚数部分,RE 和 IM 均为 float 类型,而最后的 i 是虚数单位。
声明复数的语法格式如下所示:
1 | var name complex128 = complex(x, y) |
其中 name 为复数的变量名,complex128 为复数的类型,“=” 后面的 complex 为Go语言的内置函数用于为复数赋值,x、y 分别表示构成该复数的两个 float64 类型的数值,x 为实部,y 为虚部。
上面的声明语句也可以简写为下面的形式:
1 | name := complex(x, y) |
对于一个复数 z := complex(x, y),可以通过Go语言的内置函数 real(z) 来获得该复数的实部,也就是 x;通过 imag(z) 获得该复数的虚部,也就是 y。
示例,使用内置的 complex 函数构建复数,并使用 real 和 imag 函数返回复数的实部和虚部:
1
2
3
4
5var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
复数也可以用 == 和 != 行相等比较,只有两个复数的实部和虚部都相等的时候它们才是相等的。
Go语言内置的
math/cmplx包中提供了很多操作复数的公共方法,实际操作中建议大家使用复数默认的 complex128 类型,因为这些内置的包中都使用 complex128 类型作为参数。
布尔类型
一个布尔类型的值只有2种:true 或 false。if 和 for 语句的条件部分都是布尔类型的值,并且 == 和 < 等比较操作也会产生布尔类型的值。
一元操作符 ! 对应逻辑非操作,因此 !true 的值为 false,更复杂一些的写法是 (!true == false) == true, 实际开发中我们应尽量采用比较简洁的布尔表达式,就像用 x 来表示 x==true。
1 | var aVar = 10 |
Go 语言对于值之间的比较有非常严格的限制,只有两个相同类型的值才可以进行比较,如果值的类型是接口(interface),那么它们也必须都实现了相同的接口。如果其中一个值是常量,那么另一个值可以不是常量,但是类型必须和该常量类型相同。如果以上条件都不满足,则必须将其中一个值的类型转换为另一个值的相同类型之后才可以进行比较。
布尔值可以和 &&(AND) 和 ||(OR) 操作符结合,并且有短路行为,如果运算符左边的值已经可以确定整个布尔表达式的值,那么运算符右边的值将不再被求值,因此下面的表达式总是安全的:
1 | s != "" && s[0] == 'x' |
其中 s[0] 操作如果应用于空字符将会导致 panic 异常。
因为 && 的优先级比 || 高(&& 对应逻辑乘法,|| 对应逻辑加法,乘法比加法优先级要高),所以下面的布尔值表达式可以不加小括号
1 | if 'a' <= c && c <= 'z' || |
布尔值并不会隐式转换为数字值 0 或者 1,反之亦然,必须使用 if 语句显式的进行转换
1 | i := 0 |
如果需要经常做类似的转换,可以将转换的代码封装成一个函数,如下所示
1 | // 如果 b 为真,btoi 返回 1;如果 b 为 假,则返回 0 |
数字到布尔型的转换非常简单,不过为了保持对称,我们也可以封装一个函数
1 | // itob 报告视为未非 0 |
Go 语言中不允许将整型强制转换为布尔型。如下
1 | var n bool |
布尔型无法参与数值运算,也无法与其他类型进行转换。
指针
与 Java 和 .NET 等编程语言不同,Go 语言为程序员提供了控制数据结构指针的能力,但是并不能进行指针运算。Go 语言允许你控制特定集合的数据结构,分配的数量以及内存访问模式,这对于构建运行良好的系统是非常重要的。指针对于性能的影响不言而喻,如果你想要做系统编程,操作系统或者网络应用,指针更是不可或缺的一部分。
指针(pointer) 在 Go 语言中可以被拆分为两个核心概念:
- 类型指针,允许对这个指针类型的数据进行修改,传递数据可以直接使用指针,而无须拷贝数据,类型指针不能进行偏移和运算。
- 切片,由指向起始元素的原始指针,元素数量和容量组成。
受益于这样的约束和拆分,go 语言的指针类型变量即拥有指针高效访问的特点,又不会发生偏移,从而避免了非法修改关键性数据的问题。同时,垃圾回收也比较容易对不会发生偏移的指针进行检索和回收。
切片比原始指针具备更强大的特性,而且更为安全。切片在发生越界时,运行时会报出宕机,并打出堆栈,而原始指针只会崩溃。
要明白指针,需要知道几个概念:指针地址、指针类型 和 指针取值,下面将展开详细说明。
指针地址和指针类型
一个指针变量可以指向任何一个值的内存地址,它所指向的值的内存地址在 32 和 64 位机器上分别占用 4 或 8 个字节,占用字节的大小和所指向的值的大小无关。当一个指针被定义后没有分配到任何变量时,它的默认值为 nil。指针变量通常缩写为 ptr。
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go 语言中使用在变量名前面加 & 操作符来获取变量的内存地址(取地址操作),格式如下
1 | ptr := &v // v 的类型为 T |
其中 v 代表被取地址的变量,变量 v 的地址使用变量 ptr 进行接收,ptr 的类型为 *T,称作 T 的指针类型,* 代表指针
指针实际的用法,可以参考下面的例子来了解
1 | package main |
代码说明如下:
- 第8行,声明变量 cat
- 第9行,声明变量 str
- 第10行,使用
fmt.Printf的动词%p打印 cat 和 str 变量的内存地址,指针的值是带有0x十六进制前缀的一组数据。
提示: 变量、指针和地址三者的关系是: 每个变量都拥有地址,指针的值就是地址。
从指针获取指针指向的值
当使用 & 操作符对普通变量进行取地址操作并得到变量的指针后,可以对指针使用 * 操作符,也就是指针取值,代码如下
1 | package main |
运行结果
1 | ptr type: *string |
代码说明:
- 第 10 行,准备一个字符串并赋值
- 第 13 行,对字符串取地址,将指针保存到变量 ptr 中
- 第 16 行,打印变量 ptr 的类型,起类型为
*string - 第 19 行,打印 ptr 的指针地址,地址每次运行都会发生变化
- 第 22 行,对 ptr 指针变量进行取值操作并赋值给变量 value,变量 value 的类型为 string
- 第 25 行,打印取值后 value 的类型
- 第 28 行,打印 value 的值
提示: 取地址操作符
&和取值操作符*是一对互补操作符,&取出地址,*根据地址取值地址指向的值
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下
- 对变量进行取地址操作使用
&操作符,可以获得这个变量的指针变量。 - 指针变量的值是指针地址。
- 对指针变量进行取值操作使用
*操作符,可以获得指针变量指向的原变量的值。
使用指针修改值
通过指针不仅可以取值,也可以修改值。
前面已经演示了使用多重赋值的方法进行数值交换,使用指针同样可以进行数值交换,代码如下:
1 | package main |
输出结果
1 | 2 1 |
代码说明如下
- 第 6 行,定义一个交换函数,参数为 a、b,类型都为
*int指针类型。 - 第 9 行,取指针 a 的值,并把值赋给变量 t,t 此时是 int 类型。
- 第 12 行,取 b 的指针值,赋给指针 a 指向的变量。注意,此时
*a的意思不是取 a 指针的值,而是 “a 指向的变量”。 - 第 15 行,将 t 的值赋给指针 b 指向的变量。
- 第 21 行,准备 x、y 两个变量,分别赋值为 1 和 2,类型为 int。
- 第 24 行,取出 x 和 y 的地址作为参数传给
swap()函数进行调用。 - 第 27 行,交换完毕时,输出 x 和 y 的值。
提示:
*操作符作为右值时,意义是取指针的值,作为左值时,也就是放在赋值操作符的左侧时,表示 a 指针指向的变量。其实归纳起来,*操作符的根本意义就是操作指针指向的变量。当操作在右值时,就是取指向变量的值,当操作在左值时,就是将值设置给指向的变量。
如果在 swap() 函数中交换操作的是指针值,会发生什么情况?可以参考下面代码:
1 | package main |
运行结果
1 | 1 2 |
结果表明,交换是不成功的。上面代码中的 swap() 函数交换的是 a 和 b 的地址,在交换完毕后,a 和 b 的变量值确实被交换。但和 a、b 关联的两个变量并没有实际关联。这就像写有两座房子的卡片放在桌上一字摊开,交换两座房子的卡片后并不会对两座房子有任何影响。
示例:使用指针变量获取命令行的输入信息
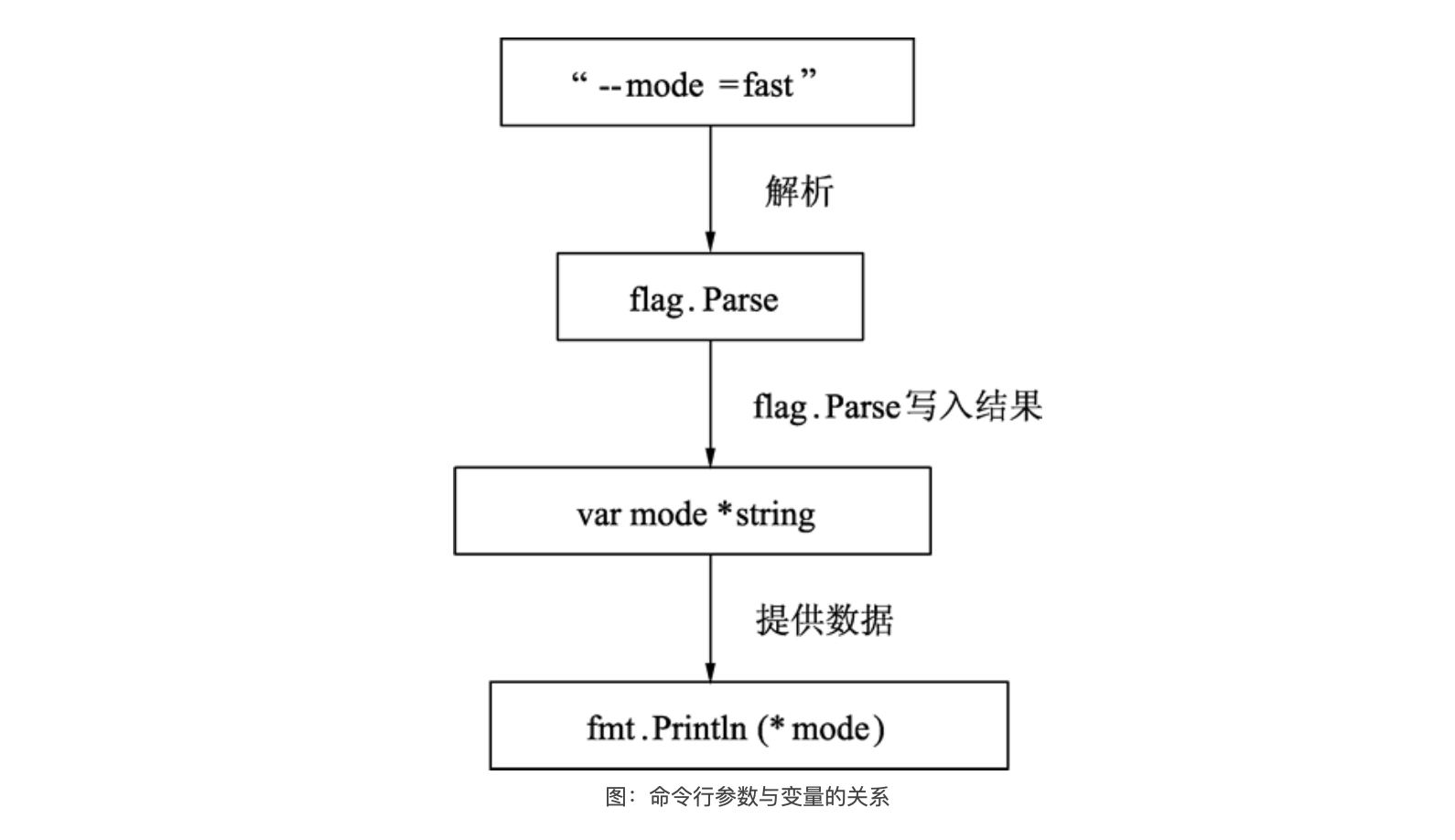
Go语言内置的 flag 包实现了对命令行参数的解析,flag 包使得开发命令行工具更为简单。
下面的代码通过提前定义一些命令行指令和对应的变量,并在运行时输入对应的参数,经过 flag 包的解析后即可获取命令行的数据
获取命令行的输入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18package main
import (
"flag"
"fmt"
)
// 定义命令行参数
var mode = flag.String("mode", "", "process mode")
func main() {
// 解析命令行参数
flag.Parse()
// 输出命令行参数
fmt.Printf(*mode)
}将这段代码命名为 main.go,然后执行以下命令
1
go run man.go --mode=fast
命令行输出结果如下
1
fast
代码说明
- 第 10 行,通过 flag.String,定义一个 mode 变量,这个变量的类型是 *string。后面 3 个参数分别如下:
- 参数名称:在命令行输入参数时,使用这个名称。
- 参数值的默认值:与 flag 所使用的函数创建变量类型对应,String 对应字符串、Int 对应整型、Bool 对应布尔型等。
- 参数说明:使用 -help 时,会出现在说明中。
- 第 15 行,解析命令行参数,并将结果写入到变量 mode 中。
- 第 18 行,打印 mode 指针所指向的变量。
由于之前已经使用 flag.String 注册了一个名为 mode 的命令行参数,flag 底层知道怎么解析命令行,并且将值赋给 mode
*string指针,在 Parse 调用完毕后,无须从 flag 获取值,而是通过自己注册的这个 mode 指针获取到最终的值。代码运行流程如下图所示。
创建指针的另一种方法
Go语言还提供了另外一种方法来创建指针变量,格式如下:
1 | new(类型) |
一般这样写:
1 | str := new(string) |
new() 函数可以创建一个对应类型的指针,创建过程会分配内存,被创建的指针指向默认值。
Go 语言数据类型转换
在必要以及可行的情况下,一个类型的值可以被转换成另一种类型的值。由于 go 语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明。
显式声明类型声明的语法如下:
1
valueOfTypeB = typeB(valueOfTypeA)
示例如下:
1
2a := 5.0
b := int(a)
类型转换只能在定义正确的情况下转换成功,例如从一个取值范围较小的类型转换到一个取值范围较大的类型(将 int16 转换为 int32)。当一个取值范围较大的类型转换到取值范围较小的类型时(将 int32 转换为 int16 或将 float32 转换为 int),会发生精度丢失(截断)的情况。
只有相同底层类型的变量之间可以进行相互转换(如将 int16 类型转换为 int32 类型),不同底层类型的变量相互转换时会引发编译错误(如将 bool 类型转换为 int 类型)。
类型转换示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29package main
import (
"fmt"
"math"
)
func main() {
// 输出个数值范围
fmt.Println("int8 range:", math.MinInt8, math.MaxInt8)
fmt.Println("int16 range:", math.MinInt16, math.MaxInt16)
fmt.Println("int32 range:", math.MinInt32, math.MaxInt32)
fmt.Println("int64 range:", math.MinInt64, math.MaxInt64)
// 初始化一个 32 位整型值
var a int32 = 1047483647
// 输出变量的十六进制形式和十进制值
fmt.Printf("int32: 0x%x %d\n", a, a)
// 将a变量数值转换为十六进制, 发生数值截断
b := int16(a)
// 输出变量的十六进制形式和十进制值
fmt.Printf("int16: 0x%x %d\n", b, b)
// 将常量保存为float32类型
var c float32 = math.Pi
// 转换为int类型, 浮点发生精度丢失
fmt.Println(int(c))
}代码说明如下:
- 第 11~14 行,输出几个常见整型类型的数值范围。
- 第 17 行,声明 int32 类型的变量 a 并初始化。
- 第 19 行,使用 fmt.Printf 的%x动词将数值以十六进制格式输出,这一行输出 a 在转换前的 32 位的值。
- 第 22 行,将 a 的值转换为 int16 类型,也就是从 32 位有符号整型转换为 16 位有符号整型,由于 int16 类型的取值范围比 int32 类型的取值范围小,因此数值会进行截断(精度丢失)。
- 第 24 行,输出转换后的 a 变量值,也就是 b 的值,同样以十六进制和十进制两种方式进行打印。
- 第 27 行,math.Pi 是 math 包的常量,默认没有类型,会在引用到的地方自动根据实际类型进行推导,这里 math.Pi 被赋值到变量 c 中,因此类型为 float32。
- 第 29 行,将 float32 转换为 int 类型并输出。
程序输出:
1
2
3
4
5
6
7int8 range: -128 127
int16 range: -32768 32767
int32 range: -2147483648 2147483647
int64 range: -9223372036854775808 9223372036854775807
int32: 0x3e6f54ff 1047483647
int16: 0x54ff 21759
3根据输出结果,16 位有符号整型的范围是 -32768~32767,而变量 a 的值 1047483647 不在这个范围内。1047483647 对应的十六进制为 0x3e6f54ff,转为 int16 类型后,长度缩短一半,也就是在十六进制上砍掉一半,变成 0x54ff,对应的十进制值为 21759。
浮点数在转换为整型时,会将小数部分去掉,只保留整数部分。